


Content-based recommendation systems for the movie night of your dreams
How Netflix is bringing the movies you want to watch to your front page

In the second part of our series on Recommendation Systems, we’re diving into content-based recommendation systems. If you missed last week’s post, check it out below for an introduction to recommendation systems and examples of their integration in technology in our day to day.

I can confidently say a majority of the items in my closet, furniture in my house, and books that I read have made their way into my life from a content-based recommendation system. These systems are embed into the sites I frequent and help make the browsing experience, especially the online or mobile one as smooth as customers demand it to be.
In a past article, we talked about microinteractions as technical norms that are expected by users universally across products, and without them, users may feel that a product is hard to use, poorly made, or even broken. We talked about pull to refresh, autocomplete in search bars, and the three-lined menu icon as examples of microinteractions.
I believe that content-based recommendations have become a microinteraction in digital shopping experiences. Consumers expect to be able to find what they are searching for, and if something similar but better exists, they expect that the given item is recommended to them during their experience. Sometimes the way we describe light blue isn’t actually the color light blue we want, or we failed to include “with handle” in the search for a trendy new Stanley cup. That’s where the algorithms come in.
We’ll talk in a later article about if this intervention is a good thing, or causing us to stray away from the preferences we have and veer towards what machines are churning out in their recommendations.
content-based recommendation systems
In last week’s intro to recommendation systems, we touched on a few content-based recommendation systems, like Amazon’s Discover Similar Items.1
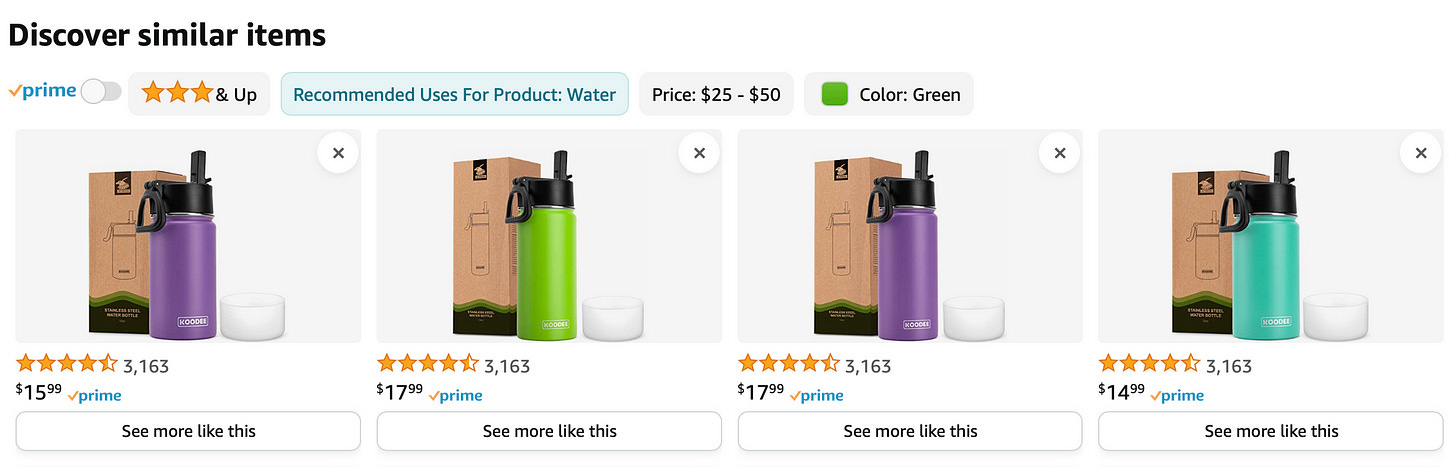
This week, we’re going to walk through Netflix’s recommendations. With just a scroll on my home page, I’ll see my top picks from Netflix:

A selection of recommendations are surfaced based on the attributes of movies and feedback I’ve provided on movies I’ve watched in the past. Feedback can be implicit in the form of viewing, minutes watched, shared via link, or explicit in the form of a rating. Let’s break down what it takes to surface these recommendations (warning: minimal mentions of linear algebra ahead).
With Netflix as an example, content based algorithm would predict More Like This recommendations, whereas collaborative filtering, the other type of recommendation system that we will cover next week, would predict Viewers Like You Watched styled recommendations, which requires other users data to generate predictions.
the basics
Let’s start with a few terms, using Netflix’s More Like This recommendation system to guide us:
User: the individual who will be receiving the prediction, who is browsing on Netflix clicking through shows trying to find something to watch. You only need one user’s data to build a content-based recommender.
Item: what will be surfaced through the recommendation. Every movie and show on Netflix is an item in their system.
Attributes: the characteristics of an item, and what will be used to build the idea of preference in our model. Attributes for items on Netflix include genre, actors in the movie, run time, and more.
how content-based recommendations work
Content-based recommendations focus on one user and their viewing history. We need to get a mathematical representation of a single user’s data on Netflix to build an algorithm from. For this example, we will use implicit feedback from our user to measure their interests.
We create two vectors:
User vector: Let’s get the implicit feedback of every movie for one single user, defining implicit feedback here as having watched a movie in the past with a given attribute. If they haven’t watched a movie with a given attribute, let’s designate that with a 0.
Item vector: For a given movie M, we need to represent the attributes that movie has and does not have.
the user-items matrix
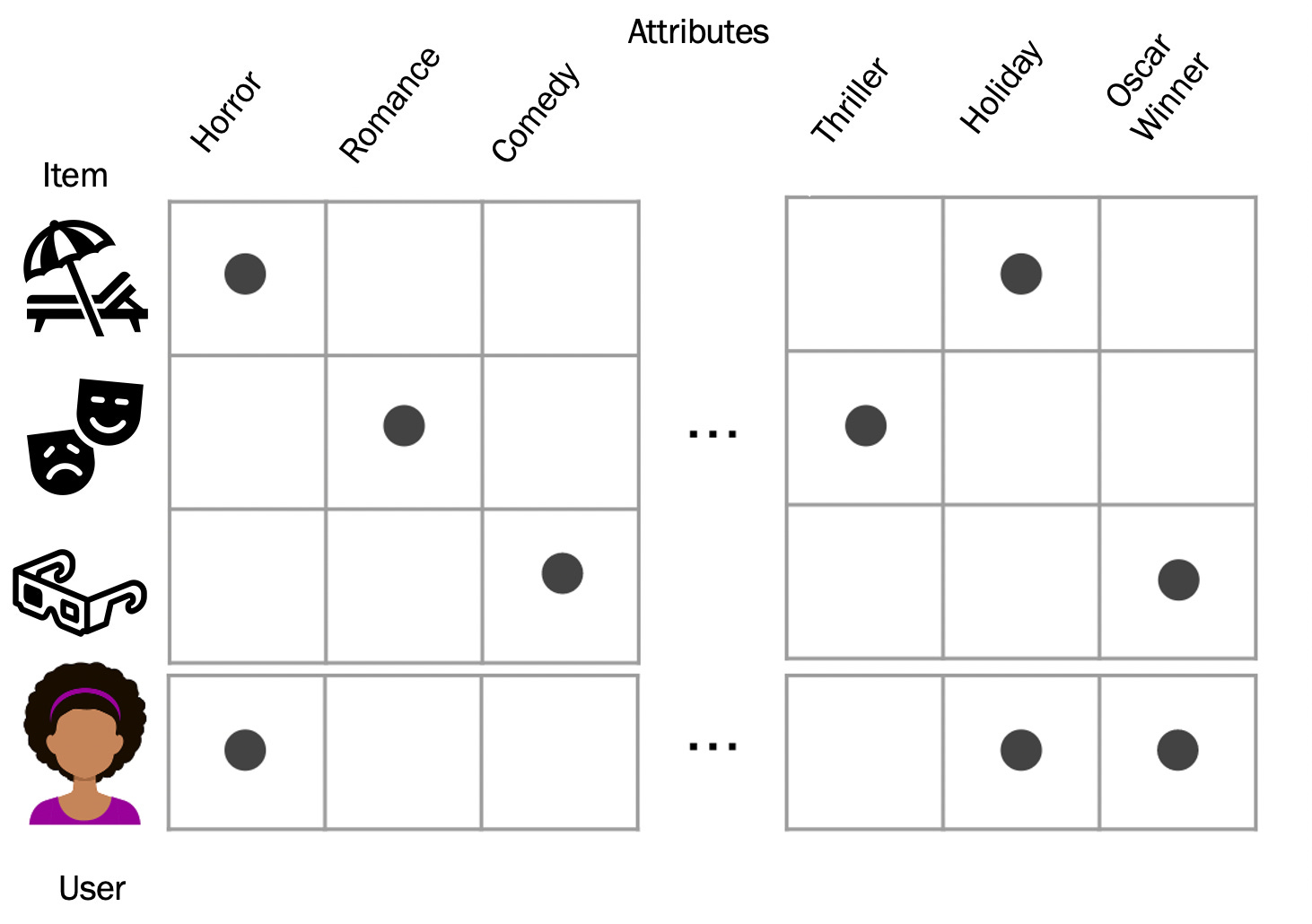
How to interpret this graphic2: Each of the first three rows is a movie (item) that has some attributes and does not have others. The last row represents a user who has interacted with items that have these attributes. Mathematically, these are represented in vectors and matrices. With each dot being a 1 and each blank spot being a 0.
Our user vector is [1,0,0,0,1,1], the first movie vector is [1,0,0,0,1,0] and so on.
From the last row, we begin to build an idea of the user’s preference. They like horror movies, holiday movies, and Oscar winners. Next time this user is looking for a movie to watch, what should we recommend?
similarity metrics
We have two different vectors of data: a user vector and an item vector. We want to calculate how similar a user is to every item. To do so, you must pick a similarity metric, which is a broad term to the set of metrics that measure the similarity of two items.
A few similarity metrics include the dot product and cosine similarity. For the math behind the scenes, check out the links I’ve added here. What we’re looking to find with these similarity metrics is how close our user vector is to every item vector in the space? By using the similarity metric to get a value that represents how close our user is to every item in the space, we can rank the output of our chosen similarity metric to use as results for predictions for our recommendations!
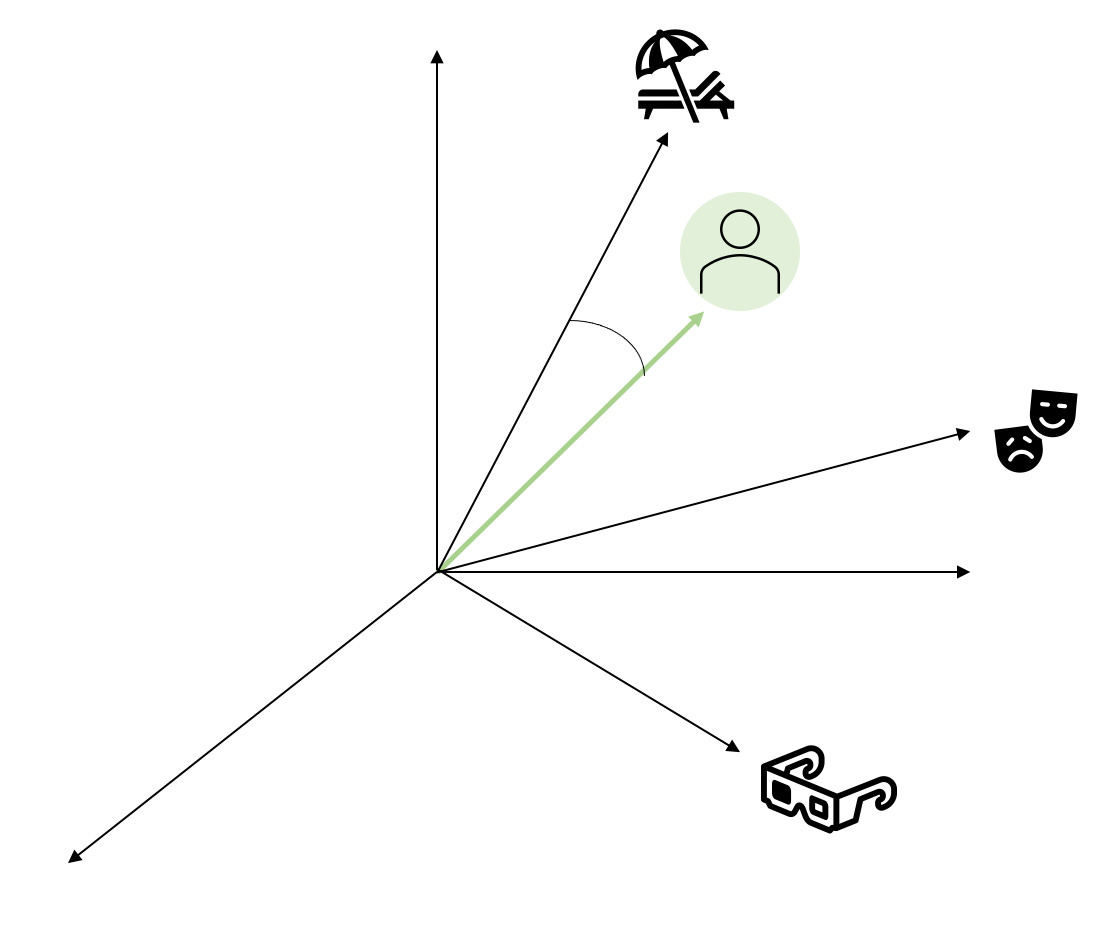
finding the best recommendation
By choosing the dot product as our similarity metric, we can use some simple math to calculate how close our user vector is to every item vector in the space. If you’re scared of linear algebra (I was for a while!), maybe close your eyes for a few seconds and scroll past, but it can be boiled down to very simple math, I promise!
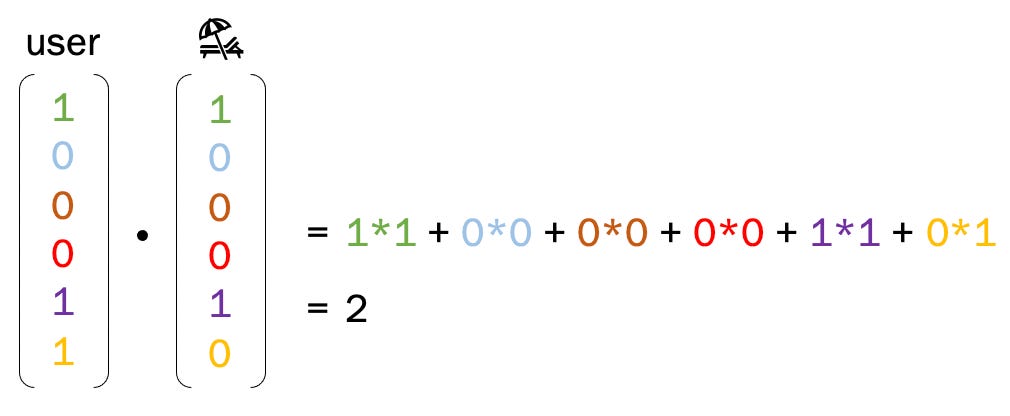
If we were to calculate the dot product for every movie and filter out items our user has already seen, we’d see that the beach movie has the highest value and therefore is our recommendation for our user!
now you’ve got recommendations!
With some simplifications, we’ve been able to walk through the foundations of a content-based recommendation system. Starting from gathering user’s preferences and attributes of items in our system, we can use a similarity metric to rank how similar our user’s preferences are to items they haven’t seen in the space.
Recommendation systems are incredibly powerful, being drivers of business value, user retention, and customer satisfaction. Content-based systems are just one type of recommendation system that can be used to enhance a platform’s ability to recommend their users high-value content that they want to see. Next week, we’ll explore collaborative filtering models as we continue exploring recommendations in this four-part series. Thanks for reading!
Footnotes
Companies today are building recommendation systems that are far more complex than just one content-based or collaborative filtering algorithm. Applications are utilizing hundreds of algorithms, building networks of relationships and analyzing billions of pieces of data to make predictions on their platforms. For the sake of simplicity, I may refer to a real product as using a single type of recommendation system, when they may be layering several types or use different systems depending on the user, item, etc. The foundational elements still stand and give sufficient background and understanding to the user on how these recommendations are generated.
https://developers.google.com/machine-learning/recommendation/content-based/basics