


Compression is the star of the show.
How a TV show led academics to think about how we can measure performance in compression algorithms.

I love Silicon Valley (the TV show of course).
Today, we’re talking about compression, including the story about how a fictitious show about tech nerds led a team of academics to developing never-before-used performance metrics that peaked the curiosity of compression researchers in the real world post-production. We’ll wrap up with a brief (emphasis on brief) technical overview of the vast field of compression.

The Silicon Valley storyline.
With minimal spoiling, I’ll give those of you who haven’t watched a TLDR.
A bunch of developers are living in a hacker house in Silicon Valley working on a company that specializes in compression - upload a photo, video, 3D file and compress it with little to no loss. Lossless compression one may say. The show follows the trials and tribulations of the team as they navigate the woes of life at the startup known as Pied Piper. After lots of hard work and obstacles, they find themselves at a startup competition, competing against fictitious behemoth Hooli to see which company has a better compression algorithm. Both companies have to show their stuff and wait for a fateful moment to see who performs best, with their success depending on one metric — a Weissman score.
The biggest spoiler I learned about the show just while researching this post: the Weissman score was MADE UP. Not just the value the algorithms achieved, sure, stuff like that’s made up in TV all the time. The Weissman score didn’t even exist until the show came along.
An algorithm made for TV.
HBO was hard at work developing a show about a startup, Pied Piper, tackling a niche problem that could be understood by a non-technical audience. The producers had landed on compression as a “a simple concept to comprehend, though not always easy to execute” that could make for some good TV. They brought on Jonathan Dotan, a tech advisor who had startup experience working in Silicon Valley, who with help from Google, found an expert in compression — Stanford professor Tsachy Weissman.
Weissman brought in Vinith Misra, a Ph.D student, to work on making an algorithm for a method of lossless compression that would result in any file type being compressed with no loss of quality that was believable, complex, but probably impossible.
“We had to come up with an approach that isn’t possible today, but it isn’t immediately obvious that it isn’t possible,” says Misra. “That is, something that an expert would have to think about for a while before realizing that there is something wrong with it.” It would pass, he said, a Powerpoint test, that is, in a Powerpoint presentation you could convince even technically knowledgeable people that it might be theoretically possible; it’s just when you sit down to build it that you run into insurmountable problems. — Source
Misra came up with an approach for the early seasons of the show: use traditional compression techniques to result in a compressed file, then calculate the difference between the compressed file and the original and compress that information. With the compressed file, and the difference between compressed and original, you have “lossless compression”.
While this is not possible to execute, this approach is commonplace. I actually talked about a similar idea in how Uber approaches predicting driver ETA’s. They apply a post-processing prediction on the error and see if they can predict the difference between actual time of arrival and predicted time of arrival in an attempt to improve their ETA accuracy. Read more here:

The metric to measure.
Weissman and Misra had an algorithm, but they needed to show just how good the fake algorithm was. This brings us to the fateful competition — a fake Techstars Disrupt — where Pied Piper goes against their competitor to see who has a better compression algorithm. The competition relied on having a metric that could compare the algorithm’s performance. In 2014, no such metric to measure compression performance existed.
Weismann says, “there are two communities: the practitioners, who care about running time, and the theoreticians, who care about how succinctly you can represent the data and don’t worry about the complexity of the implementation.” As a result of this split, he says, no one had yet combined, in a single number, a means of rating both how fast and how tightly an algorithm compresses. - Source
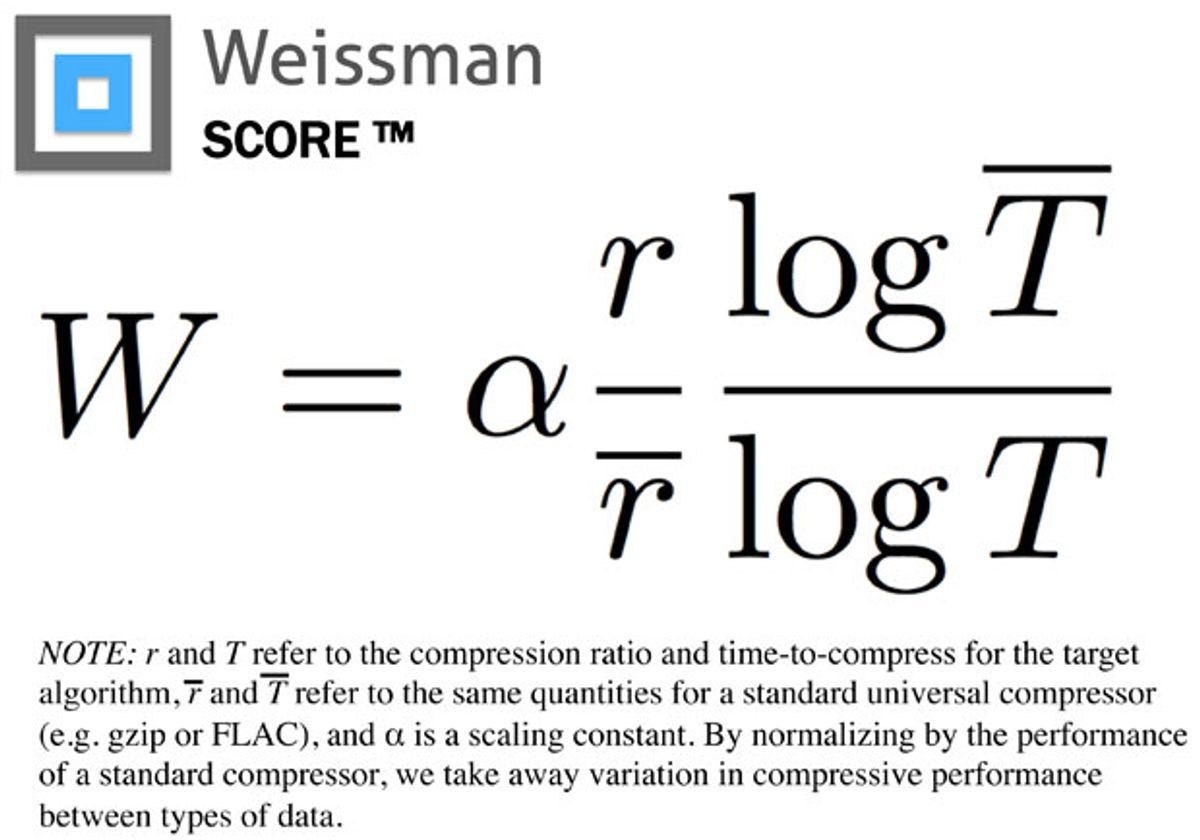
Enter the Weissman Score — it combines the compression ratio, the ratio of the log of compression time, normalized against an industry standard compressor. The score was perfect for producers to communicate to a non-technical audience which company had built a better algorithm. It translated well to television and made for an epic scene.
While the Weissman score was made for TV, it is based in reality. Weissman himself said, “I don’t want to be one who promotes a metric carrying my name but I am tempted to use it.” There’s a Weissman score calculator on Github and professors have asked Weissman to formalize the metric for use in the real world.
There’s been debate around if the Weissman score created for Silicon Valley is the best metric for measuring compression, so it hasn’t been used widely outside of the show. However, the metric has inspired dialogue about the best way to measure performance of compression algorithms as they continue to be better and faster.
With a fun story to get us to the real stuff, let’s do a quick technical overview of the basics of real-world compression.
A bit about compression
The videos on your phone, the photos on the internet, and files on your computer are able to be sent, posted, and shared thanks to compression.
From Introduction to Data Compression by Guy E. Blelloch:
Lossless compression: can reconstruct the original message exactly from the compressed message, common for text files and computer programs
Lossy compression: can only reconstruct an approximation of the original message, common for images and videos where loss of resolution is often undetectable
The process of compression typically involves two steps: encoding, where the file is made more compact, then decoding, where that process is reversed.
Run-length encoding is a lossless compression algorithm first patented in 1983. It’s a simple method that can help explain a basic approach to compression. The first sequence below could represent a line of pixels in an image. Imagine each letter represents a color block. With run-length encoding, we can compress an 8-block sequence into a 6-block representation. In the compressed version, one block represents the color, then the next block represents how many times in a row that block appears. Run-length works better for data with repeated values, which isn’t always the case in images.

A popular type of lossy compression is JPEG compression. It consists of several parts that are quite complex, including subsampling the color information in an image, discrete cosine transformation and then quantizing values. It’s pretty complex to get an image into a lossy representation of itself, but performs very well at compressing images while making the changes barely noticeable to the human eye.

{kind=link}
For a more thorough, mathy article on JPEG compression, read here.
Compression is incredibly powerful. It’s enabled much of the digital world as we know it to exist, allowing massive amounts of data to stream, share, post, send, and move around seamlessly with little to no loss of quality. And you’ve got a new fun fact for your next dinner party about how a TV show about software developers led academics to creating a fictitious set of algorithms and metrics that made for some really good TV.
Many thanks
This week’s article was inspired by the following articles and videos:
A Made-For-TV Compression Algorithm by Tekla S. Perry
A Fictional Compression Metric Moves Into the Real World by Tekla S. Perry
Weissman Score Calculators Migrate Online, But Metric Needs Some Improvements by Tekla S. Perry
ChatGPT is a Blurry JPEG of the Web by Ted Chiang
Compression by CrashCourse
Love the lesson on compression, and the reveal on the tv-made Weissman Score. All I need to do now is put my "chocolate test" into an algorithm.