


your favorite creators' perspectives in a chatbot
Using GPT3 to turn thousands of words of creator content into a chatbot with their opinions, thoughts, and personality

Welcome back to Day to Data! Today’s article talks about GPT3 and some interesting use cases, like turning your favorite creator into a chatbot. Sounds cool right?
I subscribe to a great newsletter
by . He recently shared an article (see below), written by Dan Shipper, who explained how he built a chatbot, powered by the language models in GPT3 and the text corpus from Lenny’s Newsletter archives that allowed someone to interact with a chatbot specialized in what Lenny writes about - product, growth, cool people in the space, and whatever he feels brings value to his readers that week.
Today, I want to talk about how generative text models can tackle interesting use cases, like synthesizing a creator’s opinions, perspectives, and knowledge into a chatbot that fans or leaners alike can interact with.
I haven’t talked about ChatGPT, as I’ve been focusing more on observing the discourse around the product, rather than adding my two cents on what I feel about it (not revolutionary, just easy to use) and how often I’m using it (haven’t opened the site more than 10 times). The product ChatGPT and the models OpenAI and other companies are building will continue to evolve, and I’m interested to observe what’s to come.
generative text model crash course
Let’s give a quick breakdown of how a large language model works. I am going to really gloss over some stuff here for the sake of digestibility.
Chatbots, such as ChatGPT, are an accessible way for a user to interact with large language models (LLMs). These models, while evolving as state of the art technology continues to push their success, use a few standard language processing methods to try to do what we humans do on demand - analyze data, come up with ideas, and synthesize thoughts.
How does a model learn how we speak? Just like the foundation of most machine learning models, LLMs use a lot of training data to detect patterns, expectations, and context in language.
There are two common technical elements to these large language models learning:
Word masking: Masking tokens in a phrase to the model and figuring out which word could be the best fit.
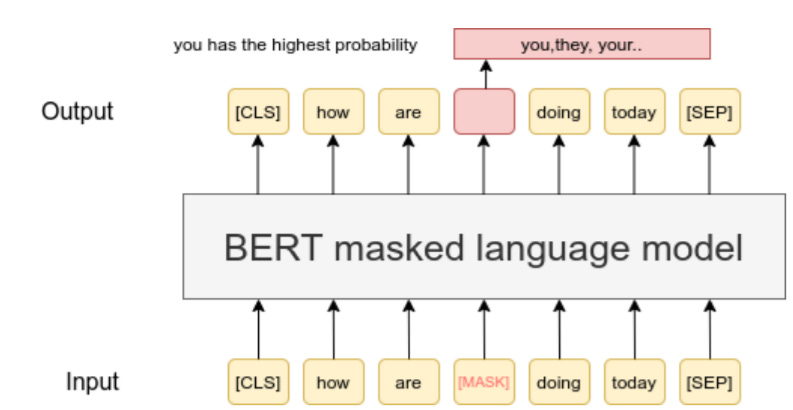
Attention: this pertains to how words in a sentence relate to one another.
For example, from The Illustrated Transformer:
”
The animal didn't cross the street because it was too tired”As a human, we know that it refers to animal, but machines can find it complex to differentiate these relationships (like whether it refers to street). This is the attention of a word.
Check out this awesome, interactive Github post for more on attention.
I’ll talk about these two topics more another day, but those two tactics help LLMs learn how to speak. If you want more details, here’s a few resources for learning:
Google’s BERT blog
what about the fun stuff?
Using what we learned about LLMs, we can understand that these models can be more finely tuned for a variety of situations depending on the instances in their training data. Specialized language models allow for better performance as the model understands context that may vary depending on the scope of the corpus.
Specialized language models include:
finBERT: trained on financial documents, and aims to understand language relating to finance better than a generic model
BioMedLM: meant to improve interpretation of biomedical language
OpenAI’s Codex: trained to turn plain language prompts into working code
There are endless possibilities for what corpus a LLM can be trained on, allowing a model to provide specific results depending on context or answers that are more specific in one corpus versus another. ChatGPT used essentially the entire internet as a corpus to train its language models on. It learned from all the StackOverflow articles, the Wikipedia entries, and billions of other sites how to best respond to your questions about bugs in your code, who ran the first marathon, or creative names for your data science newsletter. With such a broad corpus, what you gain in breadth of knowledge and ideas, you lose what I’ll call perspective and opinion.
Back to Dan Shipper - his article “I Built an AI Chatbot Based On My Favorite Podcast” caught my eye. It’s the perfect example for an interesting use case I’m excited to watch coming out of the current AI arms race that seems to have erupted this past week.
Dan used transcripts of the Huberman Labs Podcast as a training corpus for a chatbot that makes the knowledge Dr. Huberman shares in his podcast as accessible as talking to a smart friend. The Huberman Podcast is by Dr. Andrew Huberman, who shares in-depth scientific research and tools for optimizing our bodies, minds, processes, etc. His episodes are information rich and as a listener, it can be hard to parse through his past episodes if you’re looking for a specific answer to something. But with a GPT3 powered chatbot, Shipper showed the possibilities for creators everywhere to turn troves of their past episodes, blog posts, or videos into an easy to interface platform for their users to quickly get answers to their niche questions. By using the words of past podcast episodes, Dan shows how we can use GPT3 to bring back perspective and opinion.

To me, this is the more exciting part of the power of LLMs that any broad, non fine tuned chatbot like ChatGPT. Being able to interact with a chatbot that shares back specific facts from your favorite podcasters, authors, or Substack author will give users that next level of engagement that I believe has lots of potential for how creators can harness the power of artificial intelligence.
There’s an important point I hope to continue to discuss in posts to come — the technical improvements of models can be groundbreaking and life-changing, but I believe the hockey stick moment for user adoption comes from ease of use. Bringing state of the art machine learning to just anyone provides the most value when users don’t have to think twice about the complexity of what is under the hood. Integrating data science with products is adoptable by users if the integration is not just revolutionary, but easy to use.
for water cooler chatter
This week’s edition of the Hard Fork podcast talks about TikTok’s literal transparency center (described as a children’s museum for machine learning algorithms) and how ChatGPT was an accident.
SBF wants FTX’s $93 million in political contributions back. Two words: good luck.
Google’s Bard, their competitor to ChatGPT, made a factual error during a demo.
Twitter announced that they were shutting down free API usage on Feb 9th, in an unexpected tweet, angering developers who’ve made projects that drive users to Twitter. Among other Twitter news, app usage was paused on Wednesday evening giving users a slew of error messages and frustration, later reporting that an employee may have deleted data which led to the outages.

that’s a wrap.
It’s been over a month of writing about topics I’m interested in with the space of data science and product. In the coming months I hope to start sharing these posts, hearing more feedback, and writing more about data in our day to day.