


your bad handwriting won't mess with these models
recognizing your crazy cursive Gs is a piece of cake for the postal service

If you’ve taken a class in data science or read a machine learning textbook, chances are you’ve come across the MNIST database. It looks a little something like this:

Yep, a massive collection of handwritten digits (70,000 to be exact) that have been used over and over again in machine learning to train image classification models.
Remember last week’s definition of labeled data in a supervised machine learning problem? For a refresher, a supervised machine learning problem means we have a large historical training dataset with instances for which we know the “correct” prediction (aka label). For the MNIST dataset, this data being labeled would mean that for each image of a number, we knew the correct label (number) for that image. We would know that the whole first row in the above image is “zero”, the second row is all labeled “one” and so on. This may seem obvious to a human but machines can be quite stupid. Humans tend to help out in a supervised machine learning problem.
Now, think about the last time you sent a letter (I know it’s probably been a while), and how you may have scribbled the recipient’s address across the front in your potentially illegible handwriting. The letter goes in a mailbox to be processed by the USPS. Your letter is one of the 128.9 billion that the USPS processes (that was the 2021 total which was down from 142.6B in 2019; 2022 data has yet to be released). So how do they process all this mail quickly, getting it to the right location, no matter how messily your scribbled handwriting wrote the address?
The USPS has seen just about every possible way to write a ‘G’, ‘x’, ‘!’, or any other character, after years and years of digitized mail processing. They have a massive historical training dataset of successfully matched addresses with which they can compare new mail addresses, landing on a prediction for which they believe is the most likely to be the right address. With all this historical data, they built powerful text classification model that turns your scribbled words into a machine based instruction for a mail sorting machine as to which zip code your Aunt Susan lives in.
Today we’re talking about making machines read, text classification, and the law of large numbers.
machines haven’t always been able to read.
Within image detection, there is a practice called Optical Character Recognition (OCR). This development was revolutionary in the data entry and image-to-text space, allowing documents to be processed by machines to be turned into electronic text that can be used in downstream classification, analysis, sorting and more.
how does OCR work?
OCR’s goal is to recognize text in an image. Since we’re dealing with images, the process starts with a camera. The input could be a photo taken with your phone, a PDF imported from a scanner, or any other source.
While OCR has evolved over time, and each program works a bit differently, there are a few key steps:
Gather the input image.
Preprocess the image to make it easier for the machine to read.
Several possible techniques, including:
Align skewed characters
Enhance contrast to separate black text from a white background
Isolate characters that appear combined in the input image
Match the pre-processed text
Main methods include:
Pattern matching
Compare a single character to a character stored in the machine’s history.
Feature extraction
Separate a single character into lines, loops, curves, and other parts that make up the original character. Use these components as inputs to find stored characters with similar components to the character being analyzed part by part.
so the post office uses this?
Yep, they do. And they have been for a while. Check out this video by the Smithsonian for a history of mail sorting by the USPS (jump to 4:21 if you want to only hear about OCR).
For a recap, a camera is scanning each piece of mail that comes to the post office, and then matches that image to other images they’ve seen in the past. In order to match the images, they can use OCR and text classification to match the characters in the image the camera has taken to characters they have in their massive trove of data. Keep reading for more on text classification.
text classification
Once the image has been captured, and OCR has converted that image to machine readable text, we can use text classification algorithms to further distinguish what topics, categories, and labels can be applied to the text.
What’s the purpose of text classification? To sort, group, and label text data into pre-defined categories.
What types of labels are used in text classification? Any type of label could be used. Common labels include tags for what the topic of the text is (i.e. news labels could include politics, sports, or business), the tone of the text (i.e. happy, sad, mean, excited), or a domain specific category (i.e. breakfast, lunch, or dinner for recipe titles or spam or not spam for email text).
What types of text classifiers exist?
These classifiers all use different mathematical approaches to matching the input text to the most likely label.
I want to learn more! Check out Scikit Learn’s overview to Working With Text Data, this Practical Guide to Text Classifiers or this more technical Text Classification Overview.
the law of large numbers
While it may not seem like it plays a role here, the Law of Large numbers plays a crucial role in all types machine learning.
Definition time! The Law of Large Numbers states that as a sample grows in size, the average of the sample gets closer to the average of the whole population. Think about M&Ms. If your full population is a bag of 100 M&Ms, the distribution of colors in a sample of 50 will more closely match the distribution of colors in a full bag than a sample of 5, 10, 20, etc. A sample of 75 will match the distribution even more closely, as the sample is starting to more closely represent the entire population (aka that delicious bag of 100 M&Ms.
How does the Law of Large Numbers (LOLN) apply to machine learning?
The larger your training dataset gets, the more closely it starts to represent the entire population.
Aka the more letters the USPS scans, the closer it is to having representations of every font, handwriting, size, and shape in its dataset.
As the sample more closely represents the whole, the machine learning models get better at predicting, classifying, and identifying the correct match for text.
For more implications in machine learning, read here.
In the data science industry, you’ll hear a lot that a model cannot be applied to a problem because there isn’t enough data. In a world so seemingly inundated with data, there are plenty of cases for which there aren’t enough recorded instances to build accurate, high performing machine learning problems yet.
i use OCR every single day.
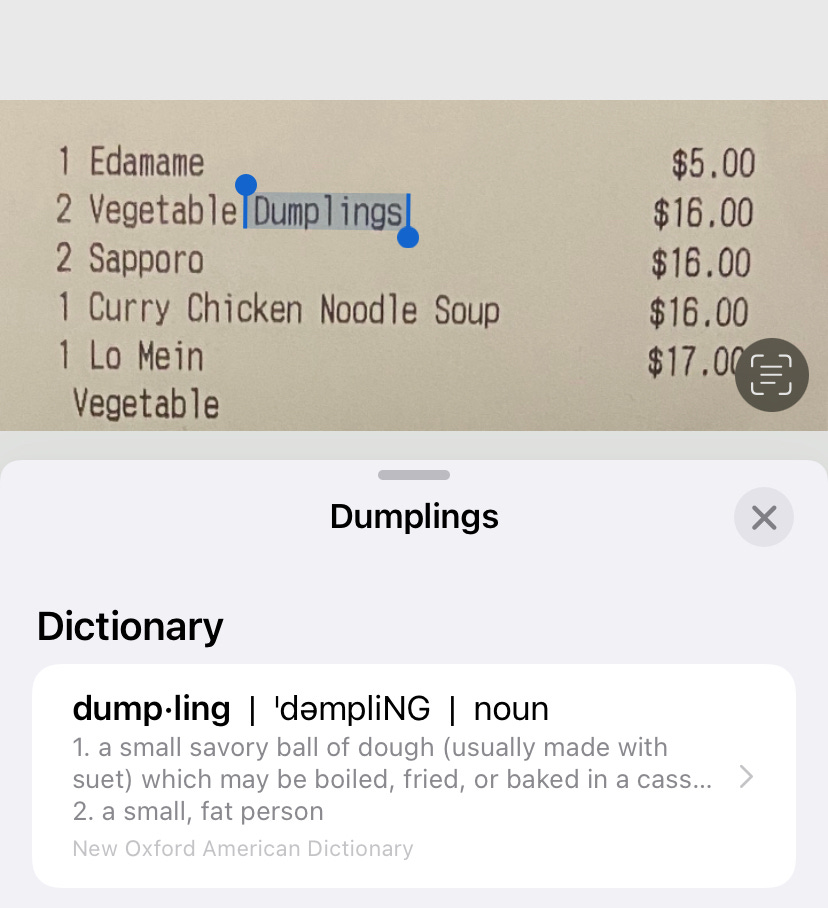
Saying the post office uses OCR may be an antiquated example, but there are exciting usages of OCR popping up all the time. My favorite? In Apple’s iOS 15 software, they released Live Text. Live Text enables the reading of text from images to then be able to send that image in a text, call the number, view the website or more.
Here’s an example: splitting the bill for a dinner last week means I’ve got photos the receipt making sure to get the Venmo’s after (paying so I get the airline miles, you know the drill). Looking at the receipt, I can merely press down on any text in the receipt and grab the text from it, making it easy to look up a term, or copy it into a text to a friend letting them know just how much to pay for the ‘dumplings’.
Popular OCR services include Amazon’s Textract, features in Adobe Acrobat, and Google’s Cloud Vision API.
There’s examples of OCR in our everyday that have seamlessly integrated with the products and software we already use. OCR is getting really freaking good and it is exciting to watch the recognition get very close to human-like. For the machines’ sake, I’ll write all my addresses a little neater this year, knowing fair well their machines would recognize my handwriting either way.