


The state of open source today
Plus, how open source competes with big tech in revolutionizing the LLM space.

Welcome to Day to Data!
Did a friend send you this newsletter? Be sure to subscribe here to get a weekly post covering the technology behind products we use every day and interesting applications of data science for folks with no tech background.
If you missed last week’s article building up the history of the open source movement, be sure to give it a read to place us where we are at today.

“We have no moat”.
These words, shared in an internal document supposedly from a researcher at Google, portray the lack of defense that a large company like Google, or their competitors like OpenAI and Microsoft, could have against large language models and platforms being developed by the open source community. Now that we know about open source and some history of the movement that got us here, let’s talk about where we are today.
Open source for generative artificial intelligence
We haven’t even skimmed the surface on the capabilities of generative artificial intelligence yet. But today, we’re going to start to discuss some of the principals being established around responsible development while also presenting some of the gaps the industry is facing. There are plenty of other use cases for open source technology that exist outside of large language models, but to frame the conversation around what’s discussed in much of the media today, we’ll focus on LLMs.
ChatGPT is released by OpenAI
ChatGPT was released in November 2022 by OpenAI. This event snowballed much of the tech world into a frenzy of development and deployment to put out their models that could compete with what was now considered state of the art. ChatGPT was first built on top of GPT-3, a large language model (LLM) with 175 billion parameters. Researchers at OpenAI collaborated on a paper that outlined the details of GPT-3, but the model exists solely behind an API that is expensive and lacking source code. With the release of GPT-4, there were even more questions around how the model, with a reported 1 trillion parameters, was built.
Sure, OpenAI doesn’t have to open source their models. They have every right to maintain their secret sauce as a company looking to maintain a competitive edge. Things get a bit stickier when you’re working on projects that claim to potentially lead to the “disempowerment of humanity”. There’s going to be questions. There’s going to be regulation. There’s going to be trust that needs to be built. Open source empowers technologists outside of the company and researchers deploying products to be able to find vulnerabilities, understand the inner workings, and feel confident with the programs they are building on top of LLMs like GPT-4. According to Elon Musk, OpenAI was named “Open” AI to allude to open source projects it intended to deliver and it has swayed from its original intent.
Big tech responds to ChatGPT
And just like that, the flood gates opened. OpenAI’s release of ChatGPT set off a fire storm of releases from companies like Google, Meta, Anthropic and more to compete. With products like Google’s Bard hoping to take on Microsoft’s integration of ChatGPT with Bing, these companies were eager to deploy engineering and compute resources to find their niche in the generative AI market. With more products came more questions around the accessibility, safety, cost, regulation, and democratization of LLMs.
They have no moat
The response to the actions of big tech? Teams around the world set to work to open-source models that could compete with the well-funded and well-staffed teams of big tech. And that’s where Google’s “we have no moat” sentiment comes into play. Several highlights in the leaked internal document from Google:
Vicuna-13B is an open source chatbot that reportedly achieves 90% of the quality of ChatGPT and was trained for around $300 — Google has comparable models costing $10M with 540B parameters.
Innovations using LoRA — aka Low Rank Adaptation — dramatically decreased the time, memory, and parameters needed to maintain high performance in Alpaca-LoRA, another open source project
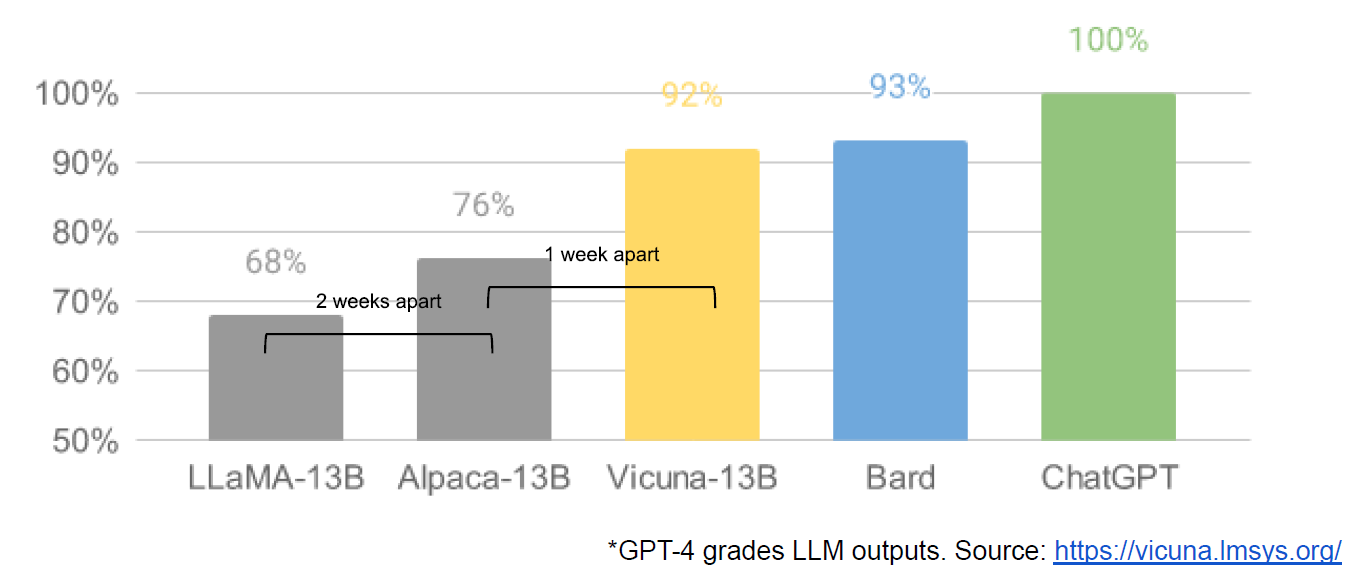
Open source was outperforming the biggest models on a dollar per parameter scale. From the leaked document, Google and OpenAI no longer had a “secret sauce”. Paying for something you could get free elsewhere wasn’t going to work. And building models with billions or trillions of parameters might get small improvements in accuracy, but sacrifice speed of development and accessibility. The performance of wildly powerful, cheap, open source projects meant that big tech might need to start showing more of their cards.
If you can’t beat ‘em, join ‘em!
On July 18, 2023, the teams at Meta and Microsoft released something big — Llama 2. Through the partnership between seemingly unlikely collaborators Meta and Microsoft, Llama 2 was released as an open-source large language model that’s available for free for research and commercial use. This was on the heels of the March leak of a first version of Llama which left developers in awe of how much it could do on one computer in a few hours. Several other companies have released open-source large language models — Databricks has Dolly and BigScience released Bloom — among other teams like the researchers behind Falcon.

Meta’s post highlights their key points for using open source —
By making AI models available openly, they can benefit everyone. Giving businesses, startups, entrepreneurs, and researchers access to tools developed at a scale that would be challenging to build themselves, backed by computing power they might not otherwise access, will open up a world of opportunities for them to experiment, innovate in exciting ways, and ultimately benefit from economically and socially.
And we believe it’s safer. Opening access to today’s AI models means a generation of developers and researchers can stress test them, identifying and solving problems fast, as a community. By seeing how these tools are used by others, our own teams can learn from them, improve those tools, and fix vulnerabilities.
I believe this was the right move for these companies. They gain trust from other technologists who can see what’s behind the product. They gain credibility with regulators and industry as they make models transparent, easy to access, and safe. Open source isn’t new for big companies. They’ve been open sourcing models, frameworks, programming languages, and more for years. But now feels like a particularly crucial time to prioritize safety over profitability. Perhaps open-source would have been better from the start, but you know what they say — if you can’t beat ‘em, join ‘em!
Want to download Llama 2? Find it here.
From Linux to Llama
Last week, we set the stage for what open source looked like in its early days. The idea of unbundling software from its hardware kickstarted a new market for products that existed outside of the hardware they were meant for (TBT to when Microsoft Word was on a CD you could install only once). Developers took this unbundling one step further, by developing software “in public”, sharing source code and letting other developers see behind the scenes. Operating systems like Linux enabled the distribution of FOSS (free, open source software). And from then on, open source became a viable competitor to tech giants.
Open source and what it means for generative artificial intelligence has created an interesting landscape. We’re seeing an increased demand for the transparency and safety that comes with open source software since the magnitude of impact that generative artificial intelligence could have feels bigger, and potentially more dangerous, than any other technology, perhaps than the internet itself, in the past decades.
It’s exciting to see big companies continue to participate in the open source space, as open source does have a track record of being a sustainable and reliable way to democratize the building and maintaining of great software and models. From Linux to Llama, the space continues to evolve and encourage great innovation I’m excited to monitor.