


The powers and pitfalls of standardized datasets
How standardized datasets can hope to improve machine learning but potentially propagate real-world biases.

Welcome to Day to Data!
Did a friend send you this newsletter? Be sure to subscribe here to get a weekly post covering the technology behind products we use every day and interesting applications of data science for folks with no tech background.
Data science needs data.
We’ll start our conversation with a look back in time. Data science truly gained traction after the tech boom in 2004-2006 (launch years of Facebook and Twitter), then exploded circa 2012, fueled by the rapidly expanding internet landscape yielding data ripe for analysis. Twitter launched their first standard API endpoint in 2012, a sign of the times where social media sites were opening up the flood gates and allowing just about anyone to pull data and dig in. As our lives moved online, data became easier to gather, analyze, and provide insights. With tools like sklearn (launched in 2007) and xgboost (launched in 2014), data scientists were ready to innovate with more machine-readable, easy-to-access data than before.
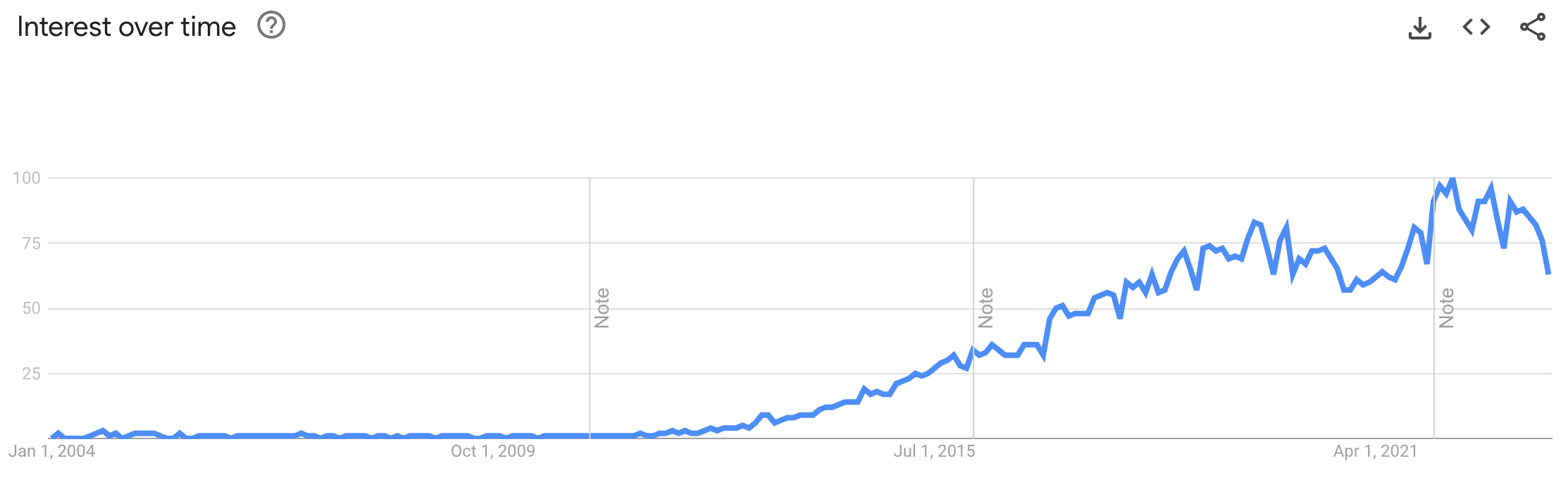
Standardizing datasets.
As models evolved and research needs for data grew, standardized datasets became a robust way to compare performance of new models. For a given area of machine learning, from facial recognition to image classification, datasets were created to make it easy for researchers to see if their work was performing better than competitors. Today we’re going to talk about two datasets that demonstrate the benefits and downfalls of standardization.
For a vast, but likely incomplete, list of common datasets used for machine learning, check out this great Wikipedia page! My middle school teacher may be rolling her eyes for citing Wikipedia, but the page is well maintained and comprehensive.
Boston housing prices
The Boston housing dataset tells an important story about propagating biases if we’re using standardized datasets to evaluate problems. The dataset was created in 1978 for David Harrison, et.al and their research on housing prices and air quality. It was derived from census data taken in Boston, MA. With only 506 instances, it is an incredibly small dataset (Remember, more data almost always means better models! Too small of a sample size can make it hard for the model to understand new data points in the future aka overfitting). The dataset has been used to teach the fundamentals of regression, using house price as the target variable for prediction.
Despite its original popularity and use, the dataset has been viewed skeptically after concerns were raised about how ethical and comprehensive the dataset is. For comprehensiveness, some of the values in the dataset were wrong and others were capped at artificial values, eliminating outliers of homes with prices higher than normal. For ethical considerations, the sklearn documentation, which has since deprecated the use of the Boston housing dataset in its package, explains it best:
“Warning: The Boston housing prices dataset has an ethical problem: as investigated in [1], the authors of this dataset engineered a non-invertible variable “B” assuming that racial self-segregation had a positive impact on house prices [2]. Furthermore the goal of the research that led to the creation of this dataset was to study the impact of air quality but it did not give adequate demonstration of the validity of this assumption. The scikit-learn maintainers therefore strongly discourage the use of this dataset unless the purpose of the code is to study and educate about ethical issues in data science and machine learning.”
Key takeaway? Always look into the data you’re using for any problem. Be skeptical of the distributions, the comprehensiveness, the bias, and the story that the data may not be telling you. Skewed or biased data is a massive problem we are seeing today with the advent of large language models and generative artificial intelligence tools, and is something researchers and users need to be critical of.
Common Crawl
The goal of Common Crawl is to provide “a copy of the internet to internet researchers, companies and individuals at no cost for the purpose of research and analysis”. The first “crawl” happened in November 2011, thanks to the incredibly talented engineer Ahad Rana and team that built the crawler to gather ~5 billion web pages that were stored in Amazon’s S3 and available to anyone. Common Crawl hoped to allow people to “indulge their curiosities, analyze the world, and pursue brilliant ideas” through the release of public, free Internet data that could power incredible models and applications. Since 2011, Common Crawl is now petabytes of web data hosted on Amazon, powering some of the most incredible data science we’ve seen in recent history. Common Crawl is the main training dataset behind Open AI’s GPT-3, where it was filtered and used for training, making up 60% of the training data the model was exposed to.

Common Crawl remains one of the best standardized datasets for large language models. The dataset is rich in human generated text and diverse in its representation of the breadth of the internet. However, there are downsides to Common Crawl — it is not in real time, the HTML format makes it heavy on the preprocessing, and there are still prevalent biases to English speaking, younger web users that drive much of the content on the internet. Some incredible AI ethics researchers, including ousted from Google’s Timnit Gebru, have posed questions on the use of a dataset such as Common Crawl in LLM’s.
What’s state of the art?
In order to gain an understanding of how data science was evolving and improving, standardization of datasets was required to establish a common starting point for algorithms to be compared to. How can you really tell if an algorithm is getting smarter if you’re comparing it across different datasets?
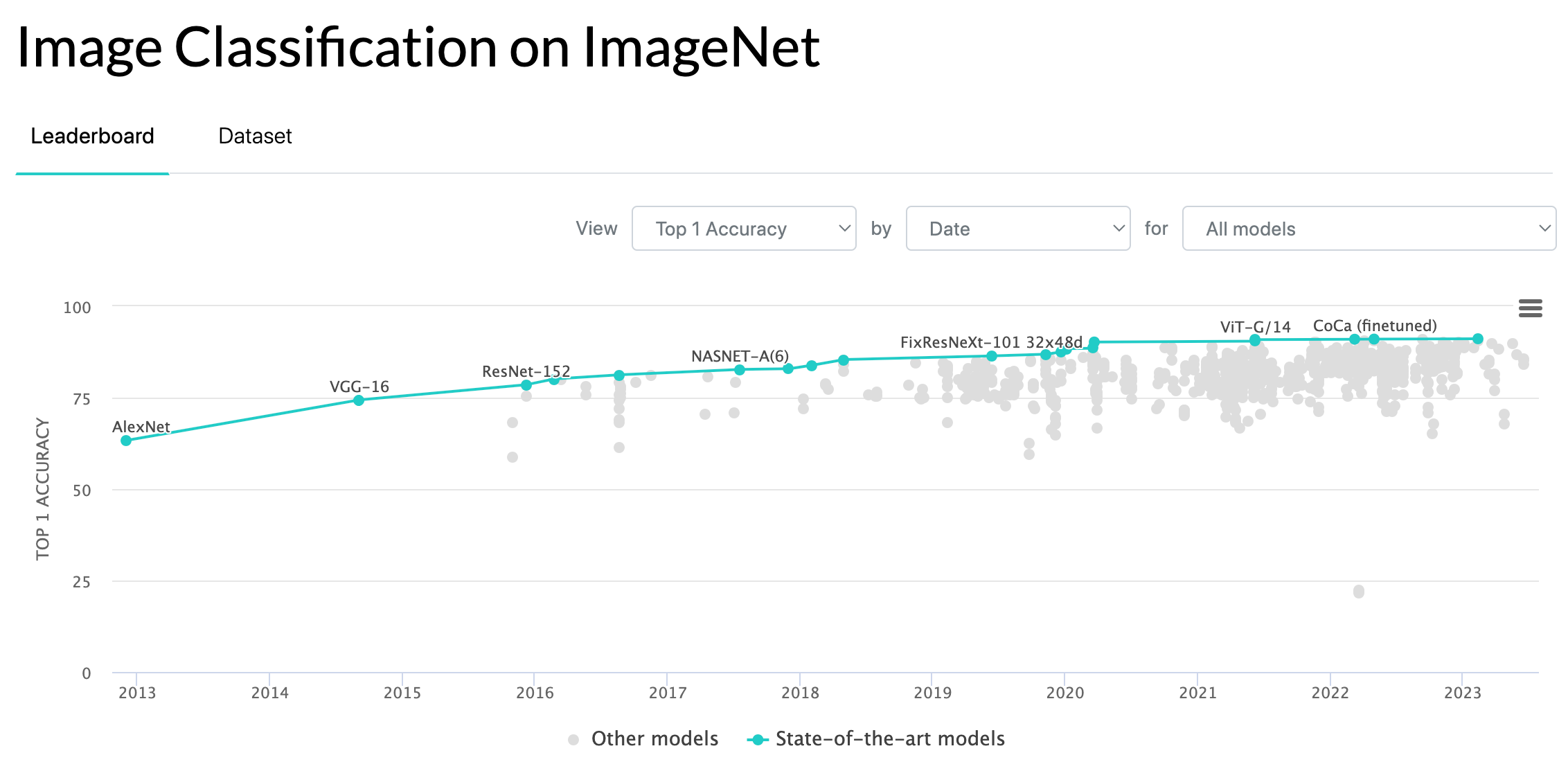
PapersWithCode is a great resource for better understanding how machine learning approaches “state of the art”. Given a machine learning task, let’s say image classification, they share associated standard datasets and the metrics achieved by various models. Shown below, you can see each data point is a model developed by researchers that tackles image classification using a given dataset, called ImageNet, and measuring a selected metric, here accuracy. The graph shows that since 2013, lots of models have been proposed, pushing the definition of “state of the art” performance measured by accuracy of the model. Common datasets, such as ImageNet, allow for the ability to see how the field is growing and models are improving, while increasing transparency for users of these models.
Want to try out some standard datasets?
Try out Sklearn’s pre-loaded datasets, with plenty of documentation, found here.
Well said. When I first heard of "big data" about twenty years ago, I doubt I imagined the datasets would get this big this quickly. I also remember more than twenty years ago trying to get out IS, math and Cs departments merge or at least collaborate on data science and analytics, yet as the inverse of the well-earned campus wisdom quip, "Debates on campus are so loud because the stakes are so low," in this case, there was no debate or discussion, and the stakes were high.