


Reinforcement learning and the power of rewards
How behavioral research with rats revolutionized the accuracy of conversational large language models.

There’s one big topic I haven’t talked much about on Day to Data yet — generative AI powered by large language models (LLMs). I’ve done a brief history of artificial intelligence — you can find the post here — but I’ve hesitated to cover LLMs, ChatGPT, etc. as there’s been plenty of coverage on the topics from technologists far smarter than myself and I’ve still got a lot of learning to do before I deliver a technical deep-dive. The best way to learn anything complex is start with the smaller stuff, and build up your understanding. So that’s what I’ll do. Today we’re talking about reinforcement learning.

At the middle school science fair.
A memorable childhood memory of mine was a middle school science fair project my sister conducted that included having her classmates eat brownies and take tests. The basics of the experiment were to see if her classmates scored better on tests knowing that they they’d get a brownie if they earned a high score, versus a group that took the tests with no reward for good performance.
It’s a classic tale of reinforcement learning, a field that wouldn’t exist without B.F. Skinner — a behavioral psychologist, researcher, and pioneer in the research of operant conditioning in the 1930s-40s.
Operant conditioning, also known as instrumental conditioning [or reinforcement learning — more commonly used in the technology context], is a method of learning normally attributed to B.F. Skinner, where the consequences of a response determine the probability of it being repeated. Through operant conditioning behavior which is reinforced (rewarded) will likely be repeated, and behavior which is punished will occur less frequently. — Saul Mcleod, PhD, for Simply Psychology
Skinner’s research involved looking at rats and pigeons (a New Yorker’s favorite animals!) in a Skinner box. This box was used to observe the behavior in response to positive reinforcers, negative reinforcers, and punishments. Two main outcomes from his studies were that positive reinforcements increase frequency of a behavior and negative reinforcements decrease frequency of a behavior. This simple statement has transformed science and technology in the years since.
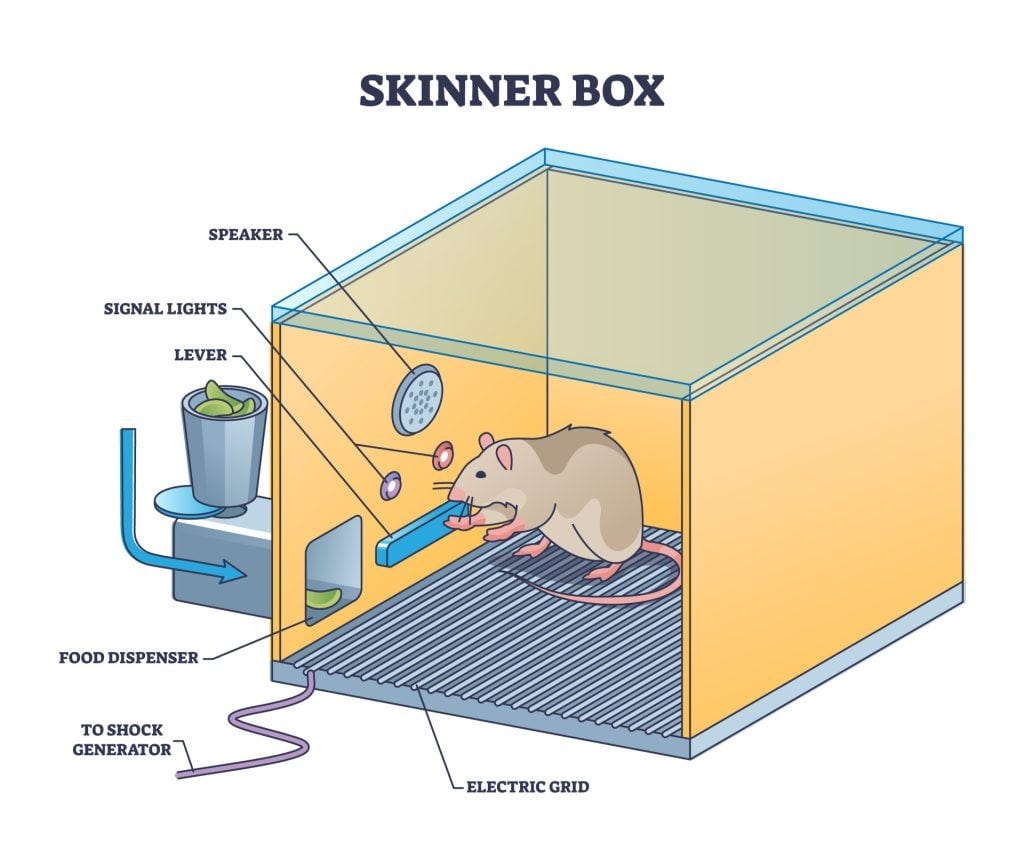
To oversimplify:
Positive reinforcement: when you scored well on a test, you received a brownie.
Negative reinforcement: to avoid being grounded, you cleaned your room.
Punishments: presenting a negative reinforcer or removing a positive reinforcer.
Skinner’s work led researchers everywhere to understand that behavior can be shaped to be as “high performing” as possible with the use of reinforcements.
How does this apply today?
With an overview of the psychology of operant learning in your back pocket, let’s pivot to how these same principles are applied to powerful machines today.
Reinforcement learning is different
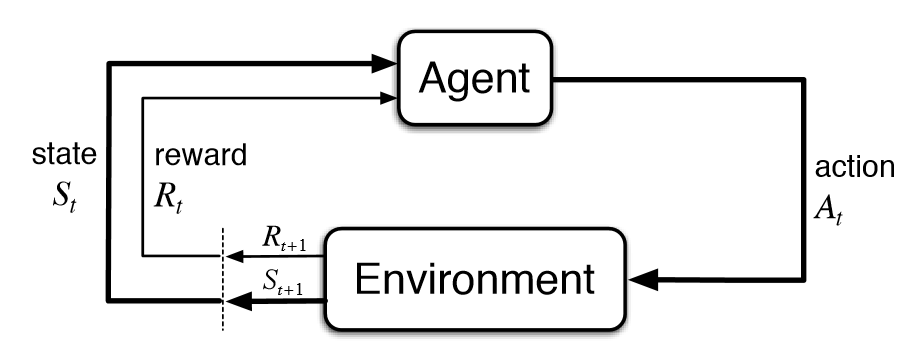
Two terms to know: agent — the decision-maker that is performing actions (ie. a human, a rat, a machine learning model) and environment — everything but the agent, what the agent interacts with to learn.
We have discussed supervised and unsupervised machine learning models. These models find patterns in data to predict, cluster, classify and more. Supervised models are fed correct outcomes for past instances that inform how to make predictions on new instances. Reinforcement learning is a third type of machine learning model, where the environment delivers a reward or punishment to the agent to enforce what types of actions to do in the future. For an example, imagine you’re a child (an agent) who is learning from your family, friends, teachers, and surroundings (your environment) how to make the right decisions every day.
Looking for a deep dive? Read Richard Sutton’s book on reinforcement learning.
Applying reinforcement learning to models
Researchers at OpenAI published Deep Reinforcement Learning with Human Feedback in 2017 and kickstarted a new wave of possibilities for reinforcement learning. OpenAI performed experiments to build out a process to use human feedback on an agent’s decisions to improve performance over time. Jesus Rodriguez’s piece in TheSequence explained the magic of reinforcement learning with human feedback (RLHF) that is behind the innovation of ChatGPT.

OpenAI posed a unique problem to their algorithm — gain enough feedback from human evaluators to get their AI model to learn to backflip. See the inflatable-balloon-on-side-of-road inspired image below for context.

From the OpenAI research:
Our AI agent starts by acting randomly in the environment. Periodically, two video clips of its behavior are given to a human, and the human decides which of the two clips is closest to fulfilling its goal—in this case, a backflip. The AI gradually builds a model of the goal of the task by finding the reward function that best explains the human’s judgments. It then uses RL to learn how to achieve that goal. As its behavior improves, it continues to ask for human feedback on trajectory pairs where it’s most uncertain about which is better, and further refines its understanding of the goal.
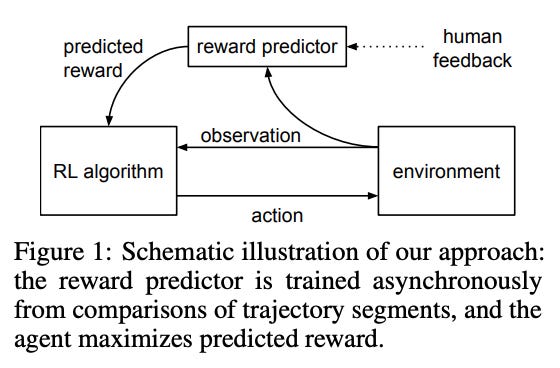
This behavior is the backbone to what makes the models and algorithms behind a product like ChatGPT so accurate. To harness RLHF to improve OpenAI’s models, a prompt is selected from their dataset, with several outputs sampled. A human labeler will then rank those outputs from best to worst, and that ranking is used to train a reward model to learn how to best respond to that prompt and other prompts in the future. The goal of each iteration is to optimize the reward model, which will help prompts in the future have responses that would lead to a high reward, aka being really good responses. By reinforcing good prompt responses versus bad prompt responses, RLHF makes conversational language models really freaking good.
Reinforcement learning in action
With reinforcement, agents can learn some pretty incredible things.

Gaming: Chess is a popular avenue for models to be trained with reinforcement. In chess, the environment clearly declares a winner and loser between two agents. An agent in chess can learn from past bad moves that led them farther away from reward (winning) to optimize performance. In 1997, IBM’s Deep Blue beat chess grandmaster Garry Kasparov in an iconic moment where reinforcement learning was put to the test.
Robotics: Stacking blocks and playing tennis are tasks robots have been trained to do, driven by reinforcement learning mechanisms built into the machines themselves. Robots learn from the environment which actions are right and wrong and work towards repeating the right ones, and not repeating the wrong ones. Want to learn more? Read How to Train Your Robot (different than how to train your dragon) with Deep Reinforcement Learning.
For more details, OpenAI’s educational resource for Deep Reinforcement Learning provides interesting applications, examples, and technical context.
Thanks for reading today’s post. We’re one step closer to understanding the more complex technical innovations of today. I’m going to enjoy my Sunday evening after sending this out by taking an evening run then getting food at my favorite spot in NYC (my version of positive reinforcement — send out a post then reward myself with good food). Have a great week!