


PageRank and scaling how we search the web
How Sergey Brin and Larry Page transformed how we search and index information.

In 1998, Sergey Brin and Larry Page published ”The anatomy of a large-scale hypertextual Web search engine” while working in the computer science department at Stanford. This paper would lay the foundation for one of the largest companies in the world — Google.
“In this paper, we present Google, a prototype of a large-scale search engine which makes heavy use of the structure present in hypertext. Google is designed to crawl and index the Web efficiently and produce much more satisfying search results than existing systems. The prototype with a full text and hyperlink database of at least 24 million pages is available at http://google.stanford.edu/”
The ability for a search engine to crawl the internet and efficiently surface relevant websites was a novel idea at the time. We’re going to walk through the revolutionary engine they built and the technology that propelled Google to build a state-of-the-art platform for indexing the growing Web.
The system to crawl the web
In order to build a powerful and accurate search engine, Google relied on “the link structure of the Web to calculate the quality rating for each Web page, designing a process called PageRank” that helped them improve the quality of search results.
We’re going to dive into the technical elements behind PageRank and explore how the results you see on Google are surfaced among the now billions of webpages that exist on the Web.
Scaling with the internet
At this time in 1998, the internet was preparing for the need to scale rapidly. In November of 1997, the highest performing search engines were indexing anywhere from 2-100 million Web documents. Brin and Page predicted that number would jump to 1 billion in the next 2 years until 2000.
Existing solutions to indexing the internet and searching the web included:
Yahoo! (1994): a human maintained index with a searchable directory
WebCrawler (1994): first to provide full text search
AltaVista (1995): searched 10 million pages in its first crawl
Google was looking to take an algorithmic approach to deciding on the quality of surfaced websites. Being able to search for key words is one thing, but surfacing the most relevant page for such key words was a problem ripe for solving in 1997.
What is PageRank?
There’s a great analogy shared in the paper around what PageRank means:
PageRank can be thought of as a model of user behavior. We assume there is a “random surfer” who is given a Web page at random and keeps clicking on links, never hitting “back” but eventually gets bored and starts on another random page. The probability that the random surfer visits a page is its PageRank.
So in practice, the Stanford University front page should have a higher PageRank than the Stanford Computer Science department page, as its statistically more likely that a random surfer would see a link to the Stanford front page rather than a page that nested deeper into the site.
Getting a high PageRank hinges on the use of links, assuming that if a website has several other websites linking to it that makes it more important. Following the example above, it’s likely that far more other websites link back to the Stanford University front page, rather than a single academic page.
To calculate PageRank, Page and Brin propose the following results:
We assume page A has pages T1…Tn which point to it (i.e., are citations). The parameter d is a damping factor which can be set between 0 and 1. We usually set d to 0.85. There are more details about d in the next section. Also C(A) is defined as the number of links going out of page A. The PageRank of a page A is given as follows:
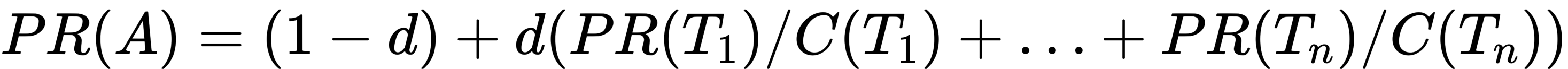
Note that the PageRanks form a probability distribution over web pages, so the sum of all web pages’ PageRanks will be one.
If you’re looking critically at this equation, you may see that the PageRank of A (PR(A)) is dependent on the PageRanks of other pages (T1, T2, etc.) which represent the pages that point to A. How can you calculate PageRank for one page that is dependent on PageRank of other pages? Where do you start? The PageRank calculation uses an iterative algorithm:
PageRank or PR(A) can be calculated using a simple iterative algorithm, and corresponds to the principal eigenvector of the normalized link matrix of the web.
Woah, woah, some big words there. To simplify this, we acknowledge that we can calculate on page’s PageRank without knowing the PageRank’s of all other pages. To get started, we can guess a PageRank value for a page in a network and then see that those guesses, when used in the iterative formula, will get us closer to the true PageRank. For a walk through of what this looks like mathematically, I found this PDF to be a great explainer.
And what’s that damping factor? From the following video, we can think of the damping factor as a method to keep an element of randomness in the equation. If d = 0.85, “85% of the time, the random [web] surfer will follow a link from the page they are currently on. 15% of the time, the random surfer will switch to a page on the internet completely at random. This ensures exploration of all webpages, rather than getting stuck at a given set.”
Some things to know:
If one page has lots of links, the value of a link on that page is less than when compared to a page with fewer outgoing links. PageRank normalizes the value of an outgoing link to a page by dividing by the total number of outgoing links on a given page.
A page is more important if linked to by other important pages.
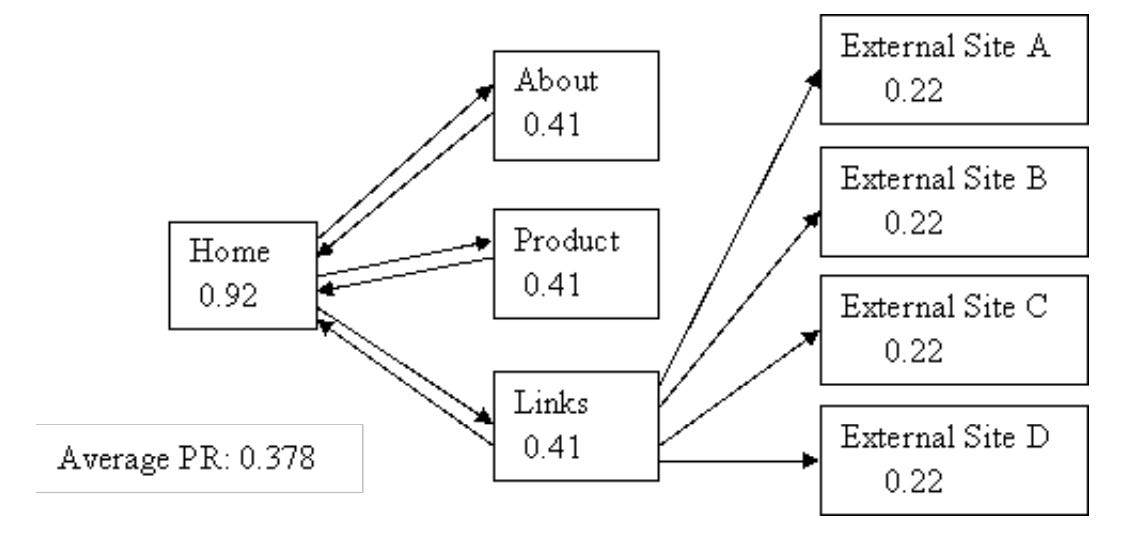
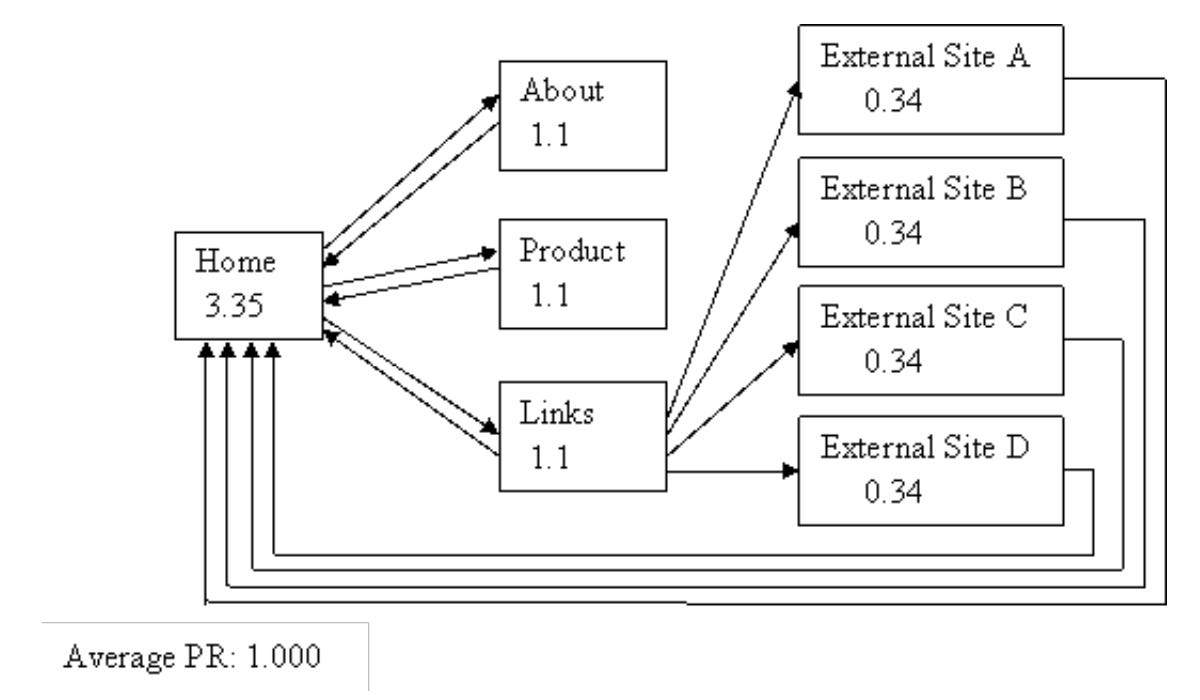
The two images above (source here) explain the importance of links. In the first network, you get a sense of how the Home page has the highest PageRank, which makes sense in terms of the random surfer analogy we used earlier. However, see that each of the external sites do not link back to the home page in the first image. When we add links from the external sites back to the home page, the home page’s PageRank jumps from 0.92 to 3.35. The average PageRank of the second network is higher than the average PageRank of the first network since the calculation place’s a heavy weight on incoming links. Let’s dive more into what this can lead to.
A good site is a well connected one.
In an internet where the priority of a page in Google’s search is driven by links, there is incentive to have lots of other pages linking back to your site. One way to do this is to just create a massive website. A news website is a good example of this. Every single news article that’s shared contains links back to the home page of the site, therefore increasing the home page’s PageRank. As mentioned earlier, a page is more important if linked to by other important pages. Hence, a good site, meaning one with high PageRank, is a well connected one.
Want to walk through more on the math behind PageRank? Check this page out.
Does search optimization make us forget?
The Google effect is an interesting phenomenon. The findings from the first study were that people are less likely to remember certain details they believe will be accessible online. Frankly, it’s something I’ve fell victim to time and time again. Sometimes I find myself Googling the most basic of facts, yet can remember niche details about a model, company, or person. The Google Effect is an interesting anecdote on the side effects of what PageRank may be helping us remember, or even forget.
Thanks for reading! Page Rank is something I’ve always wanted to discuss, and I hope to cover more in depth formulas in a later post. See you next week!
Never dampens my spirit. Always brightens my day. I always learn something,