

LLMs can be quite judgey - and it's a good thing!
LLMs can be quite judgey - and it's a good thing!
If you pit one LLM against another LLM, you just might end up somewhere.

In order to stay close to my technical roots, I started writing research briefs for folks on my teams about approaches relevant to the future of infrastructure. This week, I decided it would be fun to share one here. It’s going to be a bit more technical, so I’ll include a brief to kick us off, then dive into the nitty gritty. And as a heads up, this summer I’ll be switching to a monthly cadence, before ramping back up in September! I’ve got some thesis-driven work I’m excited to spend time on and share out after some deep dives. Day to Data has lots of fun stuff in the future!
The evolution of language models
Language models have existed for decades. They’ve become significantly larger over time (hence the “Large” ones you’ve heard about lately). In an article I wrote in early 2023, I went over some of the historically significant predecessors, like ELIZA and IBM’s Watson, which even competed on Jeopardy.

Large language models, like GPT-4 from OpenAI, have exploded in popularity and early use cases are really promising to drive value. Enterprises are hungry to implement the technology. However, many implementations are never making it to production because of concerns around how a customer-facing LLM will perform “in the wild”. These concerns have spawned an entire industry building LLM guardrails (like Guardrails AI), firewalls (like Arthur Shield), and evaluation tools (like Patronus AI). All of these techniques serve different purposes.
In terms of evaluation, early benchmarks for LLMs measured things like accuracy and perplexity, like SWE-Bench for resolving Github issues. Many early benchmarks struggled to capture how much an output from an LLM aligned with a user’s preferences. With this issue at the core, researchers were off to the races, and one of the promising releases targeting this problem was LLM-as-a-judge. Let’s dive in.
TLDR; alignment of LLMs with human preferences
(for my non technical audience, TLDR means “too long, don’t read”, and is typically followed by a short blurb describing what’s to come if you don’t want to read further!)
There is a need for a scalable, automated, and explainable method to evaluate LLM alignment based on human preferences. There is a gap with existing benchmarks on LLM performance metrics - they evaluate LLMs on standard performance metrics, but do not evaluate the LLM on human preference.
Take a look at the question below in red and the two responses of different LLMs. While both responses provide the right “answer”, Assistant B responds in a method that’s aligned stylistically to the question, more succinct, and follows the directions of the prompt more clearly, which asks for the answer only. LLM-as-a-judge is aiming to encourage LLMs to return optimized, preferred responses like Assistant B.

To do so, researchers propose that we can actually use LLMs to judge other LLMs and evaluate models. In fact, instead of using just one LLM to judge, they propose using several “LLM judges” by introducing two new benchmarks for performance: MT-Bench and Chatbot Arena.
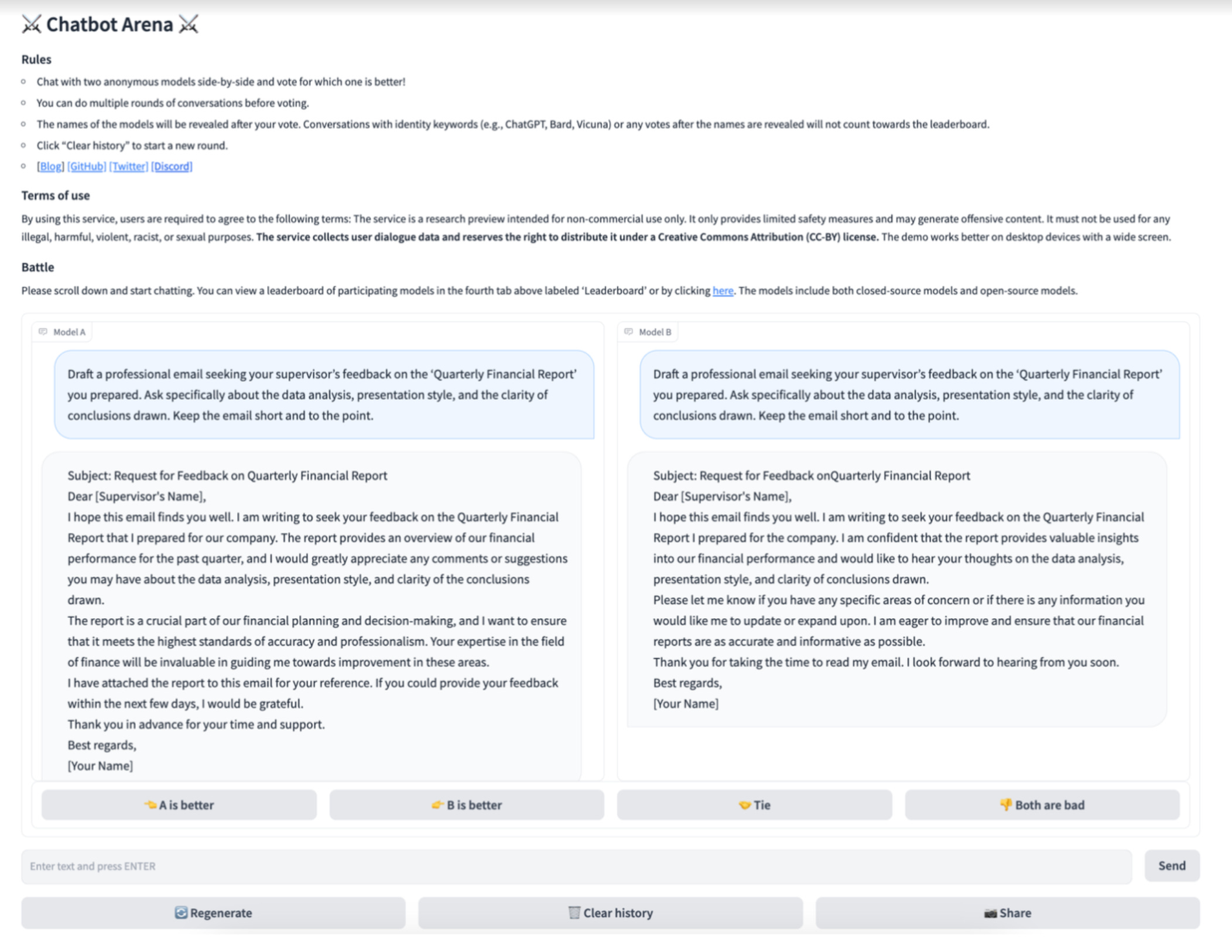
MT-bench is a series of 80 high quality, open-ended questions that evaluate a chatbot’s multi-turn conversational and instruction-following ability. Chatbot Arena is a platform where users engage in conversations with two anonymous models at the same time, posing the same question to both, and rate their responses based on personal preferences. From their research, it suggests that LLMs and a human can actually agree on the quality of an output more frequently than two humans! These methods are a promising step in the direction of more “human-like” LLM evals.
Now on to the more technical stuff….
How do we make LLMs smarter?
LLM-based chatbots saw a major performance improvement with the use of RLHF and fine-tuning. Once humans add their input through these processes, humans tend to like the outputs of the chatbot more. However, this increased alignment and preference does not correspond to improved scores on existing LLM benchmarks like HELM and MMLU. Researchers believe this suggests there is “a fundamental discrepancy between user perceptions of the usefulness of chatbots and the criteria adopted by conventional benchmarks”.
In response, this paper announced two new benchmarks - MT-Bench and Chatbot Arena.
MT-Bench
MT-Bench is a series of 80 high quality, open-ended questions that evaluate a chatbot’s multi-turn conversational and instruction-following ability – two critical elements for human preference. There are 8 categories — writing, roleplay, extraction, reasoning, math, coding, knowledge I (STEM), and knowledge II (humanities/social science). The responses to the 80 questions in MT-Bench are reviewed to measure the performance of the model in alignment with human preferences.

Chatbot Arena
This benchmark, Chatbot Arena, is a crowdsourced platform featuring anonymous battles between chatbots in real-world scenarios. Users engage in conversations with two anonymous models at the same time, posing the same question to both, and rate their responses based on personal preferences. They vote for which model provides the preferred response, with the identities of the models disclosed post-voting. Take a look below to get an idea of what Chatbot Arena can look like.
How do we get the judges to agree?
As you may have suspected, there’s some questions around what it means for all these LLM judges to “agree” on the best responses. For two judges (can be LLM or human), agreement is defined as the probability of randomly selected individuals of each type agreeing on a randomly selected question. GPT-4 and humans actually agree more often than just humans. Results reveal that strong LLMs can achieve an agreement rate of over 80%, on par with the level of agreement among human experts, establishing a foundation for an LLM-based evaluation framework.
What are the limitations?
Position bias — sometimes LLM-as-a-judge just likes the first response it reads more. This is actually not unique to LLMs - humans do this too.
Verbosity bias — an LLM judge occasionally prefers longer, verbose answers, even if they aren’t as clear
Self-enhancement bias — GPT-4 favors itself with a 10% higher win rate, Claude-v1 with 25% higher
How can I use this?
Want to use this tool for your own LLMs? Platforms like OpenPipe enable the use of LLM-as-a-judge to gauge performance of your LLMs. I haven’t used the tool myself, but engineers I’ve spoken to have spoken really highly of what they’re building here. OpenPipe completed the S23 batch of YC and raised a $6.7M seed round in March.
For enterprises, Databricks’ LLM-as-a-judge metrics were launched in MLflow in October 2023. They recommend using LLM as a judge as a companion to human evaluators.
LLM-as-a-judge is one promising tool in the suite of evaluation techniques necessary to measure the efficacy of LLM-based applications. In many situations, we think it represents a sweet-spot: it can evaluate unstructured outputs (like a response from a chat-bot) automatically, rapidly, and at low-cost. In this sense, we consider it a worthy companion to human evaluation, which is slower and more expensive but represents the gold standard of model evaluation. - Databricks
That’s a wrap!
Thank you all for reading this week’s Day to Data. As I shared earlier, I’ll be slowing things down here at Day to Data to a monthly cadence until September. I’ve got some long term projects I’m excited to focus on and will be back and better than ever going full speed this Fall! In the meantime - follow me on X at @gabyllorenzi.