


CAPTCHA the moment!
Some history on the squiggly letters and puzzle pieces that make sure we're human in an effort to fight against the rising number of bots online

Before we dive into this week’s post, I want to share an incredible initiative happening within the startup and tech ecosystem in efforts to support founders and companies in Israel strapped for resources in light of this week’s events. Volunteers can sign up here to offer their skills to be matched with Israeli startups looking for resources covering admin to tech to finance.
Check in on your friends, and support in any way you can.
I realized soon after Sunday that I did not get a Day to Data archive article out last week, and that’s on me! It was a rollercoaster of a weekend, but ended with quite the rewarding marathon in Chicago. Thank you all for the well wishes going into the race. It went great! I’m too eagerly chomping the bit to run another one soon…


This is the first article of a few on bots. Stay tuned for more!
We’ve all squinted at those letter, or searched for hidden crosswalks in photos, in an effort to sneak past the “are you a human??” portion of a website before, say, buying some concert tickets.
CAPTCHA was coined in 2000. CAPTCHA — or Completely Automated Public Turing test to tell Computers and Humans Apart — came out of research from Carnegie Mellon University, building a computer generated test that a computer itself could not pass. The Turing test was birthed in 1950 by Alan Turing in hopes of deciphering whether machines can tell the difference between humans and machines. CAPTCHA is a digital variation of the Turing test hoping to do just that. The internet was growing and folks at the forefront knew what was coming — scammers, bots, and fake madness. CAPTCHA was a gatekeeper. It was a beautiful innovation in online verification.
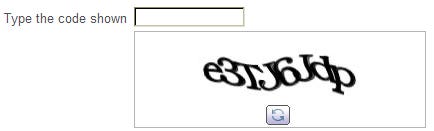
Researchers at Carnegie Mellon formally developed CAPTCHA in the early 2000s. The team, led by Luis von Ahn, was focused on eliminating spam online. They built a product that would generate images to display to web users before entering a site, making a comment, making a purchase, or doing some other online action. I’ll keep the math out of it, but there was an incredible amount of logic packed into the creation of squiggly words and hard to decipher text that spawned the CAPTCHAs we know from the early 2000s.
A team at Paypal was the first to scale the product. The Gausebeck-Levchin test was a security test Paypal engineers implemented to keep fraudsters off their platform. The engineers knew that computers struggled with vision, and that text images could be the verification method to keep spam from taking over their platform.
So I was thinking that night about, What are problems that are easy for a human to solve and hard for a computer solve?... And recognizing letters seems the archetypal example of that. I wrote an email to Max saying “Why don't we put images of characters and require a user to [put] them in? And that'll be hard to automate” — Gausebeck recalls
The dark side of CAPTCHAs
CAPTCHAs were incredibly successful, but they’ve faced some bumps along the path to success. CAPTCHAs have helped keep a majority of spam off the internet, but also have created side markets for companies that were looking to generate spam, but now needed humans to solve CAPTCHAs to do it. In 2009, sites were offering $2 for every 1,000 CAPTCHAs solved to aid in the process of spamming the web. CAPTCHA solving services became an economic machine, exploiting labor to keep spam on the web.
Another odd moment for CAPTCHA came when OpenAI released GPT-4. The supercharged model went through rigorous safety testing. One test the OpenAI development team had generated included the following —

So yes, GPT-4 was able to convince a TaskRabbit to fill out a CAPTCHA, lying its way through the process. These gates aren’t indefensible, and security teams will have to continue to iterate on the ever growing problem of spam and bots on the web.
reCAPTCHA & digitizing old books
Millions of people were voluntarily translating nonsensical images into text, which seemed, to von Ahn, like a waste of perfectly good free labor. — Source
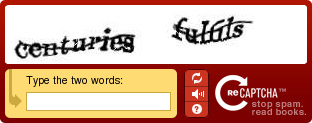
I’ve always got to end with a fun tidbit. As the CAPTCHA tool evolved, the company launched a tool called reCAPTCHA, which meant “reverse CAPTCHA”. The original version of this tool aimed to help digitize books. There were old print documents, including the New York Times archives and over 200,000 other historic books, that contained visuals that couldn’t be converted to text with the technology at the time.
reCAPTCHA fed images of these words that were hard to translate as images that verified humans on the internet. Images, like the words shown below, came from old books, and when placed at the front of websites, kept spam down and crowdsourced the digitization of old books full of illegible data. reCAPTCHA has evolved, and ended up being bought by Google to help translate documents for their Google Books product.
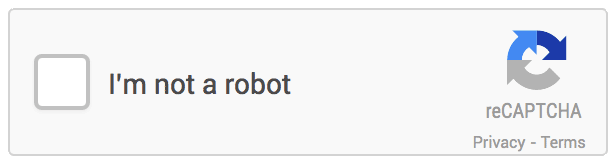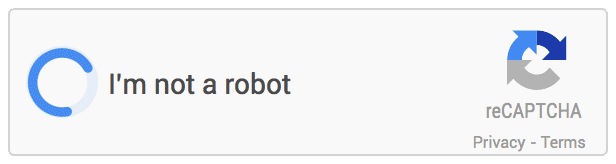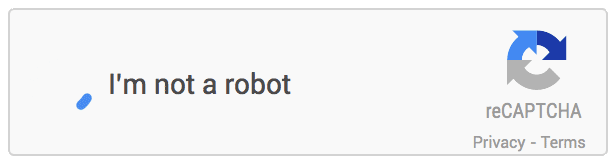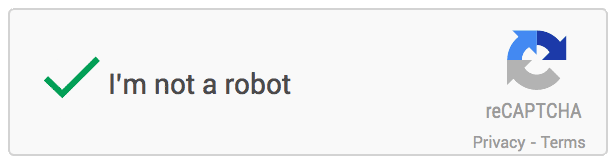
Fast forward to 2014, and AI had made strides that meant it could solve reCAPTCHAs with 99.8% accuracy. So Google went on to launch what we know of CAPTCHA today — the “I’m not a robot” click verification.
There’s something happening behind the scenes — “an Advanced Risk Analysis backend for reCAPTCHA that actively considers a user’s entire engagement with the CAPTCHA—before, during, and after—to determine whether that user is a human”, which proves to be much better at estimating human vs. machine than the older scribbly text. This product has continued to evolve, and been a major tool for Google to experiment with image labeling.
And that’s just the start of some thoughts on the history of fighting back against the bots. If you’ve made it this far, I’ll say that confirms you’re not a robot. See you next week!
Clear, concise, colorful...congratulations.