


Airbnb and housing all that data
How Airbnb standardized their data platform by bringing metrics to the forefront

Imagine you’re the CEO of Airbnb and you ask your team “Which city had the most number of bookings in the previous week?”. You’d imagine you’d get an answer right?
Well, it’s 2015 at Airbnb and you are Brian Chesky and you do just that. Your data science team comes back with one answer and your finance team comes back with another. Differing answers to a basic business metric doesn’t work if you’re a data-driven startup trying to grow rapidly and evaluate your company’s performance. This problem was a tipping point that led Airbnb to engineer an incredible metrics platform that has changed the way their teams ingest, analyze, and report on data.

{kind=link}
Today at Day to Data, we’re talking about the real world challenges of dealing with massive amounts of data. We’ll share Airbnb’s story and how their data teams built the data infrastructure that exists at the company today. Perhaps we should call this data team appreciation week!
I first heard Airbnb’s story when members of their engineering team spoke at Databrick’s Data + AI Summit. I was under a year into my full-time data scientist role and attending as many talks as possible to absorb industry knowledge. This talk to this day has stuck with me, and I’ve grown a further appreciation for how incredible their work is as I continue my career.
Feel free to watch, but we’ll share the TLDR.
Airbnb started their data journey with one full-time analyst storing all company data on a laptop, churning out expensive data queries and occasionally taking down Airbnb.com in the process.
As the amount of data and need to make sense of it all grew, their team expanded in size and they used engineering resources to evolve their ecosystem. Their team got to work developing tools, like Apache Airflow, which helped them, and now data teams everywhere, better manage their data workflows. However, your workflows can be streamlined, your teams can be collaborating well to build great products, but if the data itself is the problem, you’re not working efficiently.
Let me nerd out really quick to other technical folks reading — Since Airbnb started building Airflow, it has been open source since the first git commit!!! That is so cool!
But then came the moment that I described above, where Brian Chesky couldn’t get just one answer to his simple question. If you’re reading this and you’re not a data person, you might be thinking, what in the WORLD?! How can this billion dollar company not do a simple task?! While I too would have once been in this camp, I hope to give some perspective on the fact that first off, it was 2015, and secondly, that this is an all too common problem for companies everywhere.
foundations of the data journey
What existed before this turning point? Airbnb tackled a few key areas:
Built and scaled out an experimentation platform, with a focus on A/B testing.
Built a one stop shop in house data catalog to allow more people to use common data sources to “analyze data independently and interactively”.
Built out a data education platform called Data University to teach non-data scientists skills to democratize analytics.
Their data tables still looked, well, a mess. They had messy raw data feeding into numerous core data tables that populated their in house data catalog, which continued to get more and more complex as the data was shared to downstream apps.
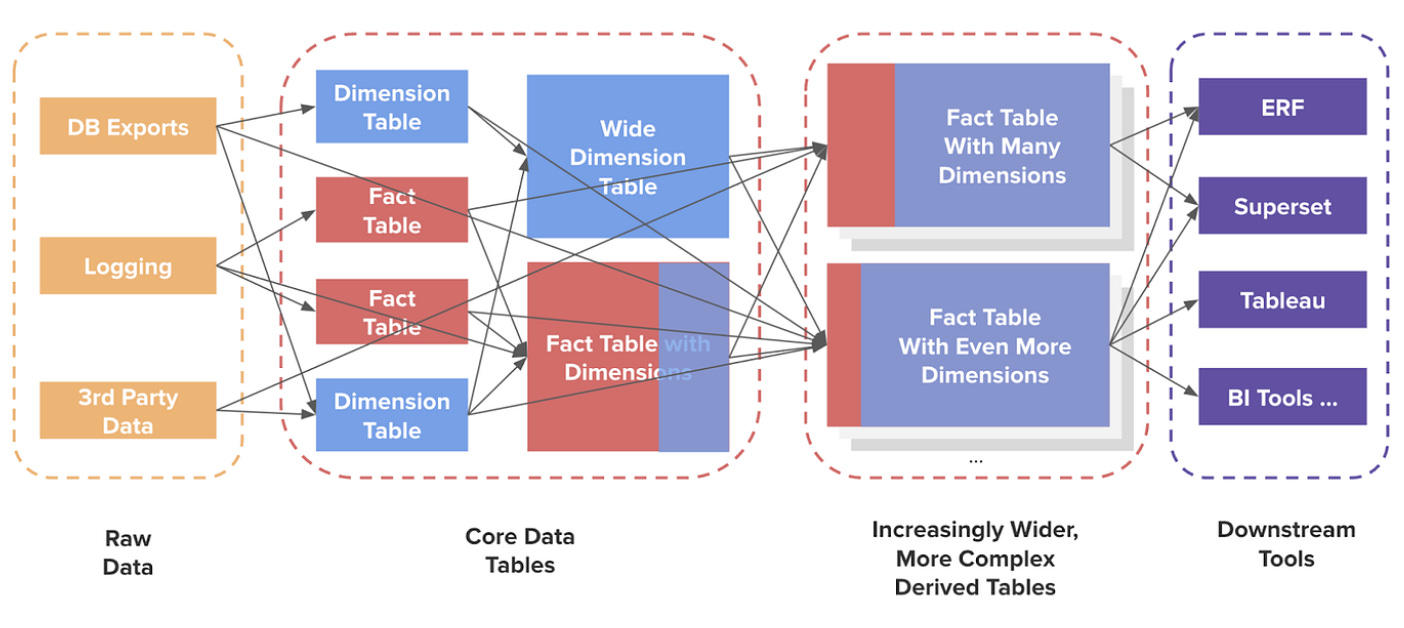
what led to minerva
While they’d made great progress, they had a pressing issue to tackle: they needed clean, aggregated data sets to easily feed into downstream tools. Enter Minerva.
Minerva transformed the way that data teams were able to use Airbnb’s data. It standardized the process for accessing “denormalized” data — a fancy term to describe prioritizing more redundancies in data for faster speed in processing.
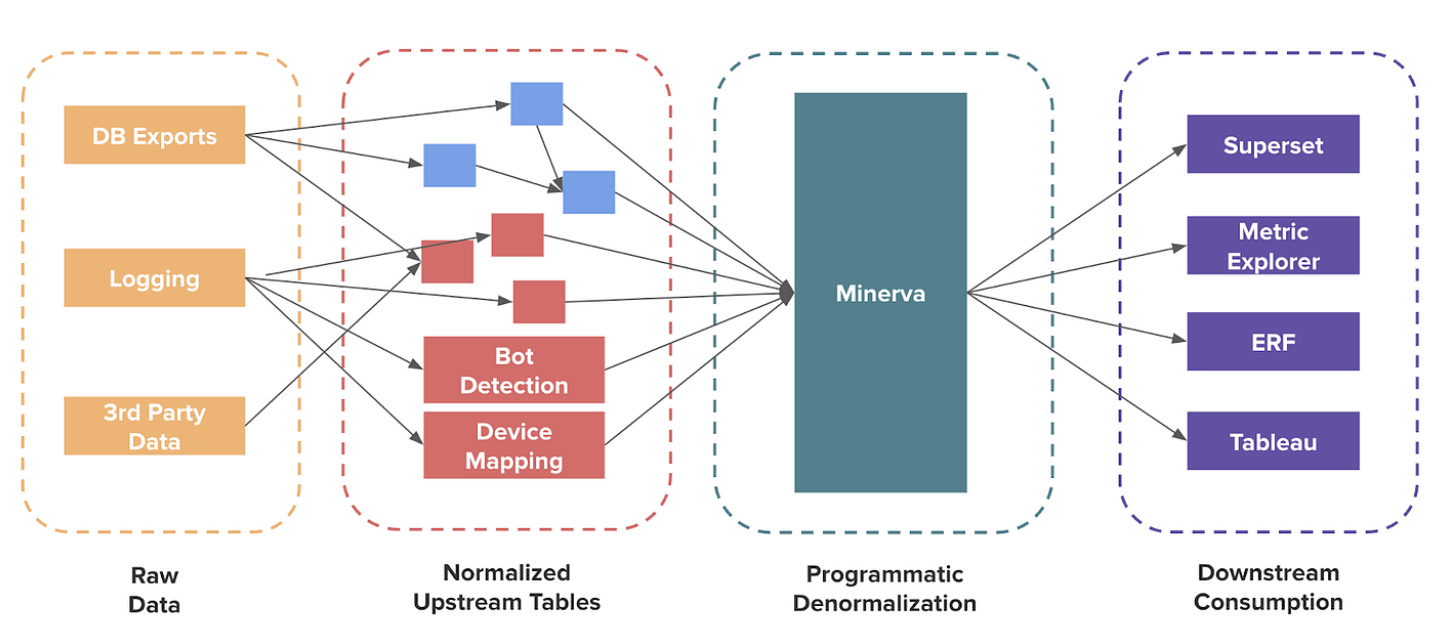
Some highlights of Minerva?
Allows users to “define metrics once, use them everywhere”
Provided an API to access data and metrics from anywhere
Automatic repair of job failures and checks for data quality
I appreciated learning about how Airbnb’s data team prioritized making data easy to search and access for non-technical team members. Anybody could look up Minerva metrics from their standardized source. One source of truth. One definition of business logic. Any team in the company was using the same data to feed into their reports, models, and downstream tools. As a data scientist, I truly understand that is a thing of beauty.
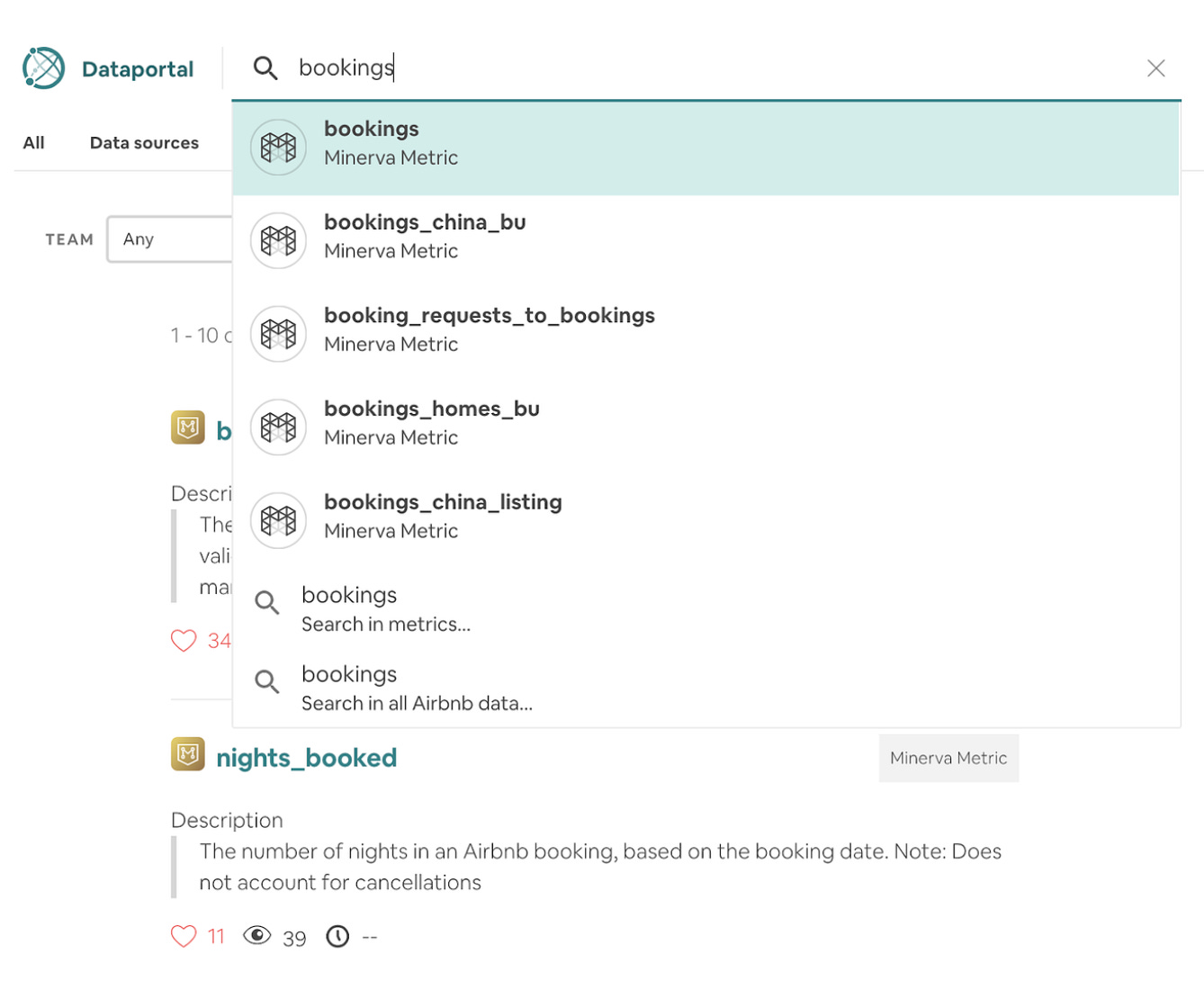
not just an airbnb problem
You may be reading this and thinking, well maybe Airbnb did something that got them to the place where they needed to truly revamp their data systems. Maybe it’s a them problem. That is not the case.
I recently listened to an episode of NerdOut@Spotify, where Laura Lake, senior director of Spotify’s Personalization Insights team, talked about how her team struggled to answer questions like “What’s the impact of someone’s home screen ranking to their downstream listening?”. Their data struggled to keep up with their needs to scale their machine learning insights. She speaks on how her team revamped the data infrastructure at Spotify to build the data-driven company we know today. This podcast is a great listen to provide a perspective of how problems with data are problems for everyone.
Thanks for reading today! This was a fun article for me. I loved learning about Airbnb’s approach to data science, with a favorite quote emerging in my research:
“Data science is an act of interpretation — we translate the customer’s ‘voice’ into a language more suitable for decision-making.” - Riley Newman, Airbnb’s first data scientist.
want to dive into this story further?
My resources, and a fun rabbit hole to go down if you’re interested, start here:
Airbnb’s talk at Databricks Data + AI Summit linked above.
Read about Data Infrastructure at Airbnb.
Check out Apache Airflow
Read this post on Superset.
Read this post by Airbnb’s Engineers
Then read this post!